Key Takeaways:
NichPR นำเสนอแนวคิดในประเด็นสำคัญดังนี้
- วิกฤต “Brain Drain” จากการเกษียณอายุของบุคลากร Gen X และ Baby Boomer สามารถแก้ไขได้ด้วยการเปลี่ยนความรู้แบบฝังลึก (Tacit Knowledge) ให้เป็นระบบดิจิทัลที่โต้ตอบได้
- การสร้าง AI Workflow ที่มีประสิทธิภาพจำเป็นต้องใช้สถาปัตยกรรมแบบผสมผสานระหว่าง LLMs, RAG (Retrieval-Augmented Generation) และ Multi-Agent Systems
- กระบวนการ 4 ขั้นตอนในการสร้าง AI Workflow เริ่มตั้งแต่การเก็บข้อมูลดิบ (Data Capture) ไปจนถึงการทดสอบความถูกต้องโดยมนุษย์ (Human-in-the-loop)
- การใช้ AI Workflow ช่วยลดเวลาในการฝึกอบรมพนักงานใหม่ลงได้มากกว่า 60% และป้องกันการสูญเสียข้อมูลสำคัญทางธุรกิจได้อย่างถาวร

วิธีสร้าง AI Workflow เพื่อถ่ายทอดองค์ความรู้จากผู้เชี่ยวชาญก่อนเกษียณ: เปลี่ยนประสบการณ์ 30 ปี ให้เป็นสมองกลขององค์กรในปี 2026
เมื่อองค์กรก้าวเข้าสู่ปี 2026 วิกฤตการณ์ที่เงียบเชียบทว่ารุนแรงที่สุดอย่างหนึ่งที่หลายบริษัทต้องเผชิญคือ **”วิกฤตคลื่นสึนามิสีเงิน” (Silver Tsunami)** หรือการเกษียณอายุการทำงานของบุคลากรระดับผู้เชี่ยวชาญในกลุ่ม Baby Boomer และ Gen X ตอนต้น ซึ่งถือเป็นฟันเฟืองสำคัญที่กุมความรู้ความชำนาญสูงสุดขององค์กรเอาไว้
ความรู้เหล่านั้นไม่ใช่เพียงแค่ข้อมูลในคู่มือการทำงาน (Explicit Knowledge) แต่คือ **”ความรู้แบบฝังลึก” (Tacit Knowledge)** ที่สั่งสมผ่านประสบการณ์ ลองผิดลองถูก และการแก้ปัญหานานนับทศวรรษ เมื่อพนักงานกลุ่มนี้เดินออกจากองค์กรไป ความรู้เหล่านี้ก็มักจะสูญหายไปด้วย
คำถามสำคัญคือ *เราจะเก็บรักษาและถ่ายทอดจิตวิญญาณแห่งความเชี่ยวชาญนี้ไว้ได้อย่างไรก่อนที่จะสายเกินไป?*
คำตอบในยุคปัจจุบันไม่ใช่การทำเล่มรายงานหนาเตอะหรือการอัดวิดีโอยาวเหยียดที่ไม่มีใครเปิดดู แต่คือการใช้พลังของ **AI Workflow** (กระบวนการทำงานอัตโนมัติด้วยปัญญาประดิษฐ์) เพื่อแปลงประสบการณ์ของมนุษย์ให้กลายเป็นระบบสมองกลอัจฉริยะที่พนักงานรุ่นหลังสามารถซักถาม เรียนรู้ และนำไปใช้งานได้จริงแบบ Real-time
ปัญหา Brain Drain ในยุคสังคมสูงวัย และทำไม KM แบบเดิมจึงล้มเหลว
วิกฤตการสูญเสีย “Tacit Knowledge” ในปี 2026
ในมิติของการจัดการความรู้ (Knowledge Management หรือ KM) ความรู้แบ่งออกเป็นสองประเภทหลัก ๆ ได้แก่:
- Explicit Knowledge (ความรู้เด่นชัด): ข้อมูลที่ถูกบันทึกเป็นลายลักษณ์อักษร เช่น คู่มือการใช้งาน นโยบายบริษัท หรือสเปกของเครื่องจักร
- Tacit Knowledge (ความรู้ฝังลึก): ทักษะ สัญชาตญาณ ไหวพริบ และวิธีแก้ปัญหาเฉพาะหน้าที่เกิดจากชั่วโมงบินของผู้เชี่ยวชาญ เช่น “การฟังเสียงเครื่องจักรแล้วรู้ทันทีว่าตลับลูกปืนกำลังจะเสีย” หรือ *”การประเมินท่าทีของลูกค้าในวิกฤตเพื่อพลิกสถานการณ์”
จากรายงานการศึกษาของ World Economic Forum พบว่าองค์กรมากกว่า 70% ต้องสูญเสียขีดความสามารถในการแข่งขันอย่างมีนัยสำคัญเนื่องจากการบริหารจัดการการเปลี่ยนผ่านความรู้ (Knowledge Transfer) ที่ไม่มีประสิทธิภาพในช่วงที่พนักงานเกษียณอายุ
ข้อจำกัดของวิธีกระดาษและวิดีโอแบบเดิม
ตลอดหลายทศวรรษที่ผ่านมา องค์กรพยายามแก้ปัญหานี้ด้วยระบบ KM แบบดั้งเดิม เช่น:
- การเขียนคู่มือมาตรฐาน (SOP): มักจะล้าสมัยอย่างรวดเร็ว และยากเกินกว่าจะครอบคลุมกรณีข้อยกเว้น (Edge Cases) ทั้งหมด
- การอัดวิดีโอสัมภาษณ์: แม้จะเก็บข้อมูลได้ดี แต่เป็นรูปแบบข้อมูลที่ไม่มีโครงสร้าง (Unstructured Data) การจะหาข้อมูลเฉพาะเรื่องจากวิดีโอยาว 10 ชั่วโมงเป็นเรื่องที่ยากและเสียเวลาอย่างมากสำหรับพนักงานรุ่นใหม่
- ระบบ Shadowing (การประกบงาน): มีค่าใช้จ่ายสูงและขึ้นอยู่กับทักษะการสอนของผู้เชี่ยวชาญแต่ละคน ซึ่งบางครั้งผู้เชี่ยวชาญที่เก่งที่สุดอาจไม่ใช่ผู้สอนที่ดีที่สุดเสมอไป
ด้วยเหตุนี้ การปฏิวัติระบบจัดเก็บความรู้ด้วย AI Workflow จึงไม่ใช่ทางเลือกอีกต่อไป แต่เป็นทางรอดที่จะรักษาเสถียรภาพและความต่อเนื่องของธุรกิจไว้ได้อย่างยั่งยืน
AI Workflow คืออะไร? พลิกโฉมการสืบทอดความรู้ได้อย่างไร
ในบริบทของการจัดการความรู้ยุคใหม่ AI Workflow คือ การบูรณาการเครื่องมือปัญญาประดิษฐ์ (โดยเฉพาะอย่างยิ่ง Large Language Models หรือ LLMs) เข้ากับกระบวนการทำงานอย่างเป็นระบบ เพื่อสกัด ประมวลผล จัดหมวดหมู่ และส่งต่อความรู้จากแหล่งข้อมูลต่าง ๆ ไปยังผู้รับปลายทางโดยอัตโนมัติ
[ข้อมูลดิบจากผู้เชี่ยวชาญ] ➔ [AI Workflow (Transcription + Structuring + Retrieval)] ➔ [AI Co-Pilot สำหรับพนักงานใหม่]
บทบาทของ LLMs, Multi-Agent Systems และ RAG
โครงสร้างพื้นฐานของ AI Workflow ยุคปี 2026 ประกอบด้วยเทคโนโลยีหลัก 3 ส่วนที่ทำงานร่วมกัน:
- Large Language Models (LLMs): ทำหน้าที่เป็น “สมองส่วนหน้า” ในการทำความเข้าใจบริบทภาษาของมนุษย์ แปลงภาษาพูดที่เป็นธรรมชาติของผู้เชี่ยวชาญให้อยู่ในรูปแบบที่เป็นระบบ
- RAG (Retrieval-Augmented Generation): เทคโนโลยีสำคัญที่เชื่อมโยง LLM เข้ากับคลังความรู้ภายในองค์กร (Internal Knowledge Base) ช่วยให้ AI ตอบคำถามได้ถูกต้อง แม่นยำ และไม่ออกอาการ “คิดไปเอง” (Hallucination) โดยการอ้างอิงจากข้อมูลจริงที่ผู้เชี่ยวชาญทิ้งไว้
- Multi-Agent Systems (ระบบตัวแทนอัจฉริยะหลายตัว): การแบ่งหน้าที่การทำงานของ AI ออกเป็นหลายบทบาท เช่น Agent ตัวที่ 1 ทำหน้าที่สัมภาษณ์และเก็บข้อมูล, Agent ตัวที่ 2 ทำหน้าที่วิเคราะห์และตรวจสอบความถูกต้อง, และ Agent ตัวที่ 3 ทำหน้าที่เขียนคู่มือและตอบข้อซักถาม การแยกส่วนนี้ช่วยให้กระบวนการทำงานลื่นไหลและมีข้อผิดพลาดน้อยที่สุด
ขั้นตอนการออกแบบและสร้าง AI Workflow เพื่อสกัดความรู้ผู้เชี่ยวชาญแบบทีละขั้นตอน (Step-by-Step Guide)
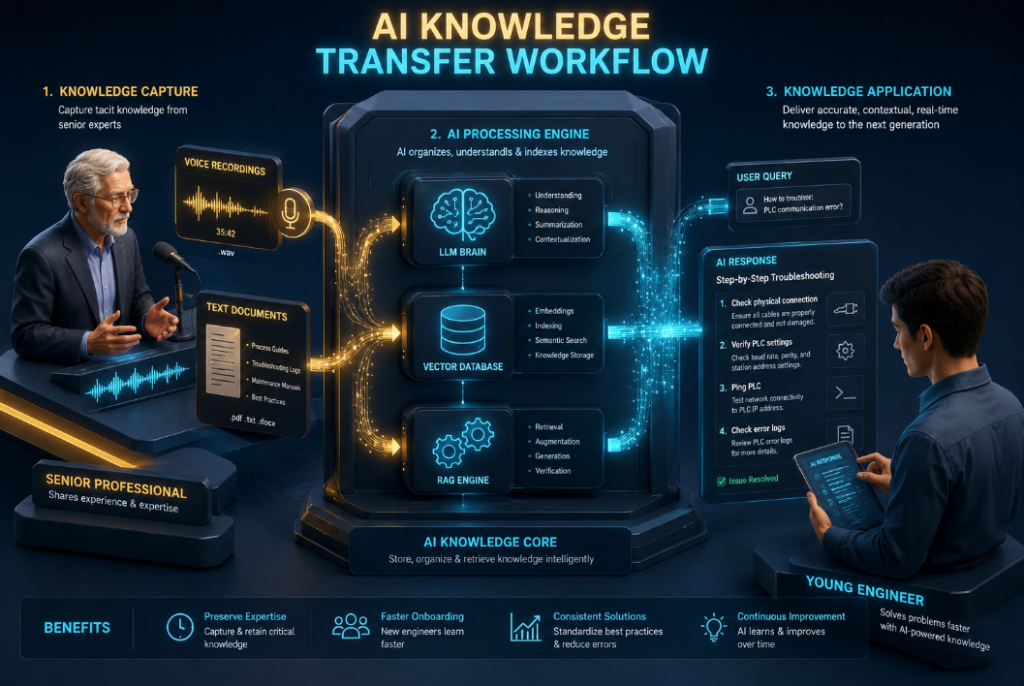
การสร้าง AI Workflow เพื่อสืบทอดองค์ความรู้อย่างประสบความสำเร็จ ไม่ใช่การซื้อซอฟต์แวร์สำเร็จรูปมาติดตั้งแล้วจบไป แต่คือการออกแบบสถาปัตยกรรมข้อมูลที่รัดกุมตามขั้นตอนดังต่อไปนี้:
| 🚀 ขั้นตอนหลัก | 📝 กิจกรรมสำคัญ | 🛠️ เครื่องมือแนะนำ (ปี 2026) | 🎯 ผลลัพธ์ที่ได้ |
|---|---|---|---|
| 🎙️ 1. Knowledge Extraction | • สัมภาษณ์ผู้เชี่ยวชาญ (Deep Interview)• บันทึกเสียงและวิดีโอการทำงานจริง• รวบรวมเอกสาร คู่มือ และ SOP | 🎤 Whisper API💬 Fireflies.ai⚙️ Dify | 📄 ข้อมูลดิบ (Raw Knowledge)🎧 ไฟล์เสียง📝 Transcript และคลิปตัวอย่าง |
| 🧠 2. Structuring & Vectorization | • ทำความสะอาดข้อมูล (Data Cleaning)• แบ่งเอกสาร (Chunking)• สร้าง Embedding และ Indexing | 🦙 LlamaIndex📍 Pinecone🧩 Qdrant | 🗄️ Vector Database🔍 Semantic Search พร้อมใช้งาน⚡ ค้นหาความรู้ได้อย่างรวดเร็ว |
| 🤖 3. Agent Integration | • สร้าง AI Agent เฉพาะทาง• เชื่อมต่อ RAG และเครื่องมือภายนอก• ออกแบบ Workflow การทำงาน | 👥 CrewAI🔗 LangChain🤖 AutoGen | 💡 AI Co-Pilot🙋 ผู้ช่วยตอบคำถามอัจฉริยะ⚙️ ระบบจำลองผู้เชี่ยวชาญ |
| 👨🏫 4. Human-in-the-Loop | • ผู้เชี่ยวชาญตรวจสอบคำตอบ• ปรับปรุง Prompt และ Knowledge Base• ประเมินความแม่นยำและความปลอดภัย | 🖥️ Gradio📊 Streamlit | ✅ AI Workflow ที่ผ่านการรับรอง🎯 คำตอบแม่นยำ🔒 พร้อมใช้งานในองค์กร |
ขั้นตอนที่ 1: การเก็บข้อมูลดิบและสร้าง “ผู้เชี่ยวชาญดิจิทัล” (Knowledge Extraction)
หัวใจสำคัญของขั้นตอนนี้คือการทำให้ผู้เชี่ยวชาญเหนื่อยน้อยที่สุด การขอให้พนักงานวัยใกล้เกษียณมานั่งพิมพ์คู่มือวันละ 3 ชั่วโมงเป็นสิ่งที่ไม่สมจริงและมักถูกต่อต้าน
วิธีการปฏิบัติ:
- การสัมภาษณ์แบบไม่มีโครงสร้างแต่เน้นเป้าหมาย (Semi-structured Interviews): ใช้ทีมงาน HR หรือทีมพัฒนาบุคคลเป็นผู้สัมภาษณ์ โดยเน้นถามถึง “กรณีศึกษาที่ยากที่สุด” หรือ “วิกฤตที่เคยแก้ไขสำเร็จ”
- การใช้เทคโนโลยีจับภาพและเสียง (Ambient Capture): ติดตั้งระบบบันทึกเสียงอัจฉริยะ (เช่น ไมโครโฟนตัดเสียงรบกวนในห้องทำงาน) หรือใช้ซอฟต์แวร์บันทึกหน้าจอขณะที่พวกเขาทำงานจริง
- การแปลงเสียงเป็นข้อความ (Speech-to-Text): นำไฟล์เสียงเหล่านั้นเข้าสู่ AI Transcription Engine ที่แม่นยำสูงและเข้าใจบริบทภาษาไทยและภาษาอังกฤษเฉพาะทางวิศวกรรม/ธุรกิจ เช่น Whisper Large V3 ของ OpenAI หรือโมเดลภาษาไทยเฉพาะทางของประเทศ

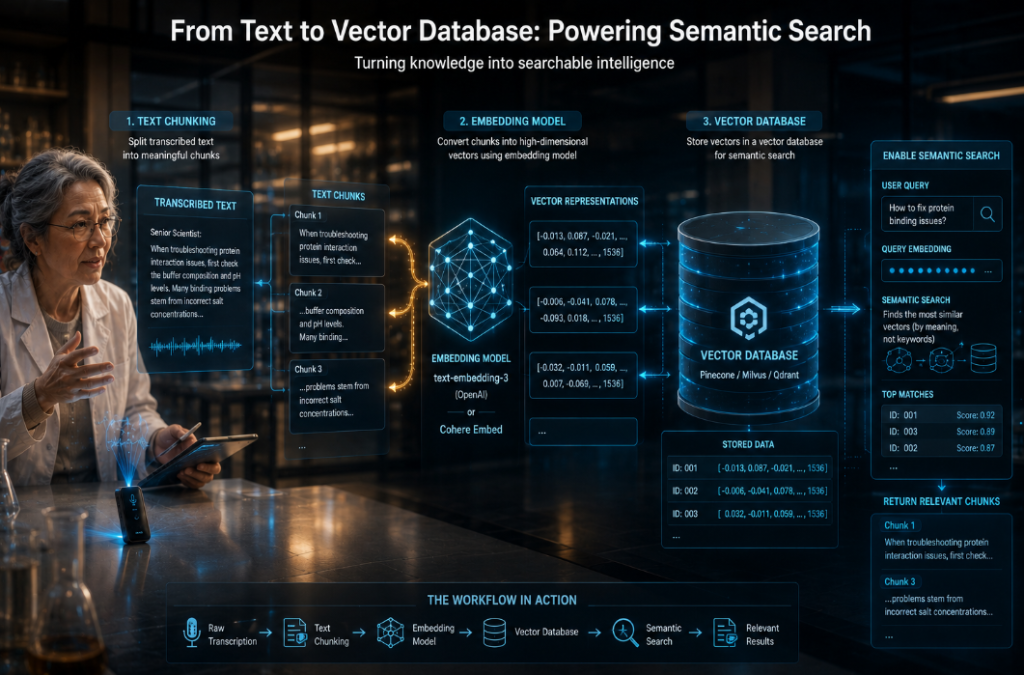
ขั้นตอนที่ 2: การจัดโครงสร้างข้อมูลด้วย RAG และเวกเตอร์ดาต้าเบส (Knowledge Structuring)
ข้อมูลดิบที่ได้จากการสัมภาษณ์มักจะกระจัดกระจายและไม่มีโครงสร้าง หน้าที่ของ AI Workflow ในส่วนนี้คือการทำความสะอาดข้อมูล (Data Cleaning) และแปลงข้อมูลเหล่านั้นให้อยู่ในรูปแบบที่เครื่องคอมพิวเตอร์และโมเดลภาษาสามารถค้นหาได้ดีที่สุด
การแบ่งท่อนข้อมูล (Chunking Strategy)
เนื่องจาก LLMs มีข้อจำกัดเรื่องขนาดของบริบท (Context Window) แม้ในปี 2026 ขนาดจะกว้างขึ้นมาก แต่การป้อนข้อมูลที่ยาวเกินไปจะทำให้ความแม่นยำลดลง เราต้องใช้หลักการ Chunking:
- Semantic Chunking: แบ่งข้อมูลตามหัวข้อหรือความหมาย ไม่ใช่แบ่งตามจำนวนตัวอักษร เช่น การสิ้นสุดการอธิบายขั้นตอนการซ่อมปั๊มน้ำดิบหนึ่งขั้นตอน ถือเป็น 1 Chunk
- Metadata Tagging: ใส่ป้ายกำกับให้แต่ละ Chunk เสมอ เช่น
[ผู้เชี่ยวชาญ: คุณสมชาย],[แผนก: ซ่อมบำรุง],[อุปกรณ์: Turbine-X],[ปีที่บันทึก: 2025]
การนำเข้าสู่ Vector Database
นำข้อความที่แบ่งแล้วไปผ่านโมเดล Embedding (เช่น Text-Embedding-3 ของ OpenAI หรือโมเดลของ Cohere) เพื่อแปลงเป็นตัวเลขชุดยาว (Vectors) แล้วจัดเก็บลงใน Vector Database เช่น Pinecone, Milvus หรือ Qdrant เพื่อเปิดใช้งานการค้นหาเชิงความหมาย (Semantic Search) ซึ่งทำให้พนักงานรุ่นใหม่ถามคำถามด้วยภาษาพูดธรรมดา ๆ แล้วได้คำตอบที่ตรงประเด็น แม้จะไม่รู้คีย์เวิร์ดที่ถูกต้องทั้งหมดก็ตาม
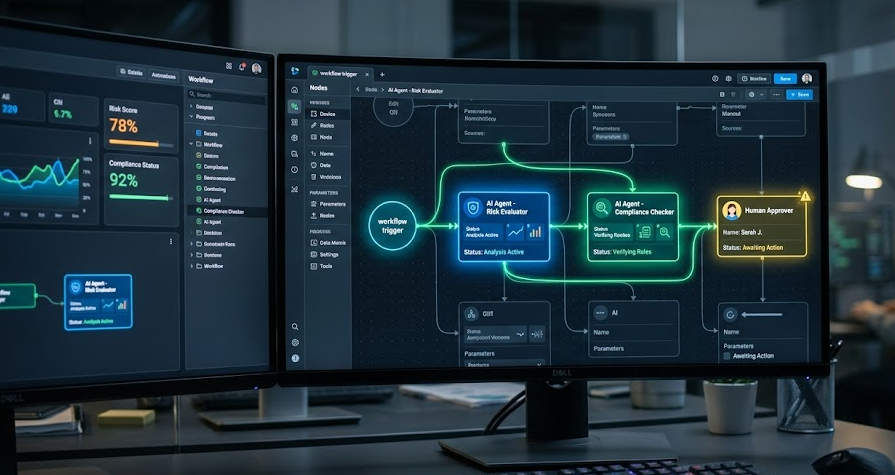
ขั้นตอนที่ 3: การสร้าง AI Agent เพื่อจำลองตรรกะการตัดสินใจ (Decision-Making Automation)
นี่คือจุดตัดที่ทำให้ AI Workflow เหนือกว่าฐานข้อมูลความรู้แบบเก่า เพราะมันไม่ได้ทำหน้าที่เพียงแค่ “ค้นหา” แต่สามารถ “คิดและตัดสินใจแทน” ได้ โดยใช้เฟรมเวิร์ก Multi-Agent
ลองจินตนาการถึงการตั้งค่า AI Agent 3 ตัวทำงานร่วมกันในคลังความรู้เกี่ยวกับ “การอนุมัติสินเชื่อธุรกิจขนาดใหญ่” ที่ได้จากอดีตผู้บริหารสินเชื่อระดับสูง:
- Agent A (The Interviewer): ทำหน้าที่รับเรื่องจากลูกค้า และตรวจสอบเอกสารเบื้องต้นตามข้อกำหนด
- Agent B (The Risk Analyst): ดึงประวัติการตัดสินใจในอดีตของผู้เชี่ยวชาญที่เกษียณไปแล้วจาก Vector Database มาเปรียบเทียบ โดยวิเคราะห์ความเสี่ยงและเขียนรายงานสรุปตรรกะเบื้องหลัง
- Agent C (The Reviewer): ตรวจสอบว่าตรรกะของ Agent B สอดคล้องกับกฎระเบียบชุดใหม่ของธนาคารในปี 2026 หรือไม่ ก่อนจะส่งต่อให้มนุษย์ลงลายมือชื่อขั้นสุดท้าย
การใช้เครื่องมือจำพวก CrewAI หรือ Dify ช่วยให้เราสามารถตั้งค่า Workflow เหล่านี้ได้ผ่านทางลอจิกภาพ (No-code/Low-code workflow builder) โดยระบุบทบาท (System Prompts) และขอบเขตเครื่องมือ (Tools) ที่แต่ละ Agent สามารถหยิบมาใช้ได้อย่างแม่นยำ
ขั้นตอนที่ 4: การทดสอบ ปรับแต่ง (Fine-Tuning) และทดลองใช้งานร่วมกับมนุษย์ (Human-in-the-Loop)
ก่อนจะนำ AI Workflow ไปใช้งานจริงในกระบวนการผลิตหรือการบริการที่สำคัญอย่างยิ่งยวด (Mission-Critical) จำเป็นต้องมีกลไกตรวจสอบความถูกต้องเสมอ เพื่อป้องกันความเสียหายต่อธุรกิจ
1. สร้างชุดคำถามทดสอบ (Gold Standard Test Set): รวบรวมคำถามที่พบบ่อยและเคสยาก ๆ ประมาณ 50-100 เคส ให้ผู้เชี่ยวชาญตัวจริงเฉลยไว้ล่วงหน้า
2. การเปรียบเทียบคำตอบ (Evaluation): ส่งคำถามเหล่านั้นเข้าไปในระบบ AI Workflow แล้วนำคำตอบที่ AI เจนเนอเรตออกมาไปเปรียบเทียบกับคำตอบของผู้เชี่ยวชาญ ใช้ตัวชี้วัดเช่น RAG Triad (Context Relevance, Groundedness, Answer Relevance) เพื่อตรวจสอบว่า AI มโนคำตอบขึ้นมาเองหรือไม่
3. Human-in-the-Loop (HITL): ในช่วง 3-6 เดือนแรกของการใช้งานจริง ควรกำหนดให้คำตอบและการตัดสินใจของ AI Workflow ต้องได้รับการยืนยันหรือตรวจทานจากพนักงานระดับอาวุโสที่ยังทำงานอยู่ก่อนที่จะส่งตรงถึงลูกค้าหรือนำไปใช้งานจริง
Use Cases: กรณีศึกษาการประยุกต์ใช้ AI Workflow ในภาคอุตสาหกรรมจริง
เพื่อให้เห็นภาพการนำไปใช้งานจริงและการสร้างมูลค่าให้กับธุรกิจ นี่คือ Use Cases เด่น ๆ ในอุตสาหกรรมหลักในปี 2026:
ธุรกิจการผลิตและวิศวกรรม (Manufacturing & Engineering)
- ปัญหา: ช่างซ่อมบำรุงอาวุโสที่มีประสบการณ์ซ่อมเครื่องจักรขนาดใหญ่มา 35 ปีกำลังจะเกษียณ มีเพียงเขาคนเดียวที่รู้วิธี “ปรับความตึงของสายพานด้วยเสียงฟัง”
- การประยุกต์ใช้ AI Workflow:
- ใช้ Smart Glasses (เช่น Meta Quest หรือ Apple Vision) บันทึกมุมมองขณะที่เขาทำการซ่อมและพูดบรรยายสิ่งที่เขาคิดในใจ
- สร้าง AI Agent ที่รับข้อมูลวิดีโอและเสียงดังกล่าวมาแปลงเป็น “คู่มือแนะนำการแก้ไขปัญหาเชิงโต้ตอบ” (Interactive Troubleshooting Copilot)
- เมื่อช่างรุ่นใหม่สวมแว่นตาอัจฉริยะขณะเข้าหน้างาน AI จะทำการตรวจจับภาพเครื่องจักรและดึงตรรกะการประเมินของผู้เชี่ยวชาญมาแสดงผลแบบ AR (Augmented Reality) แนะนำขั้นตอนการปรับความตึงแบบเรียลไทม์
ธุรกิจบริการทางการแพทย์และสาธารณสุข (Healthcare & Diagnostics)
- ปัญหา: แพทย์เฉพาะทางด้านรังสีวิทยาที่เป็นผู้เชี่ยวชาญในการอ่านผลตรวจโรคมะเร็งชนิดหายากมีจำนวนไม่เพียงพอและกำลังเตรียมอำลาวงการ
- การประยุกต์ใช้ AI Workflow:
- รวบรวมฟีดแบคและรายงานการอ่านผลแล็บย้อนหลัง 15 ปีของผู้เชี่ยวชาญมาจัดโครงสร้างผ่าน Multi-modal RAG ที่วิเคราะห์ได้ทั้งข้อความและรูปภาพฟิล์มเอ็กซเรย์
- ออกแบบ AI Workflow เพื่อคัดกรองเบื้องต้น (Triaging) โดยจัดหมวดหมู่ภาพถ่ายที่เข้าข่ายผิดปกติสูงส่งต่อไปยังแพทย์ฝึกหัด พร้อมคำอธิบายอ้างอิงจากบทวิเคราะห์ในอดีตของแพทย์อาวุโส
- ช่วยเพิ่มความรวดเร็วในการวินิจฉัยโรคและลดความผิดพลาดในการตัดสินใจลงได้ถึง 40%
ธุรกิจการเงินและกฎหมาย (Finance & Legal Compliance)
- ปัญหา: ที่ปรึกษากฎหมายของบริษัทผู้เชี่ยวชาญด้านการควบรวมกิจการ (M&A) และการวางแผนภาษีระหว่างประเทศ ซึ่งมีเทคนิคเฉพาะในการประเมินความเสี่ยงและเจรจาต่อรองกำลังจะเกษียณอายุ
- การประยุกต์ใช้ AI Workflow:
- สกัดบันทึกช่วยจำ (Memos) และเอกสารสัญญาที่เคยผ่านการตรวจแก้ (Redlines) เพื่อดึงแพทเทิร์นการต่อรองและการวิเคราะห์ความเสี่ยง
- สร้าง AI Agent สำหรับการร่างและตรวจสอบร่างสัญญาฉบับเริ่มแรก (Drafting) ที่มีไวยากรณ์และความคิดเฉียบคมตรงตาม “แนวทางของคุณประพันธ์” (อดีตหัวหน้าฝ่ายกฎหมาย) ทำให้ลดระยะเวลาการทำงานของพนักงานระดับจูเนียร์ลงอย่างมหาศาล
ความท้าทายและการควบคุมจริยธรรม (Ethics & Governance) ในการใช้ AI Workflow
แม้ระบบ AI Workflow จะให้คุณประโยชน์มหาศาล แต่การนำเทคโนโลยีนี้ไปปรับใช้อย่างขาดการวางแผนจริยธรรมและการกำกับดูแลอาจก่อให้เกิดความเสียหายร้ายแรงต่อทรัพย์สินทางปัญญาและความสัมพันธ์ภายในองค์กรได้
ประเด็นลิขสิทธิ์ทางปัญญาและความเป็นส่วนตัวของข้อมูล
- ใครคือเจ้าของความรู้?: เมื่อสกัดความรู้จากพนักงานก่อนเกษียณแล้ว บันทึกเหล่านั้นถือเป็นทรัพย์สินขององค์กรตามกฎหมายแรงงานส่วนใหญ่ แต่อย่างไรก็ตาม องค์กรควรระบุข้อตกลงอย่างเป็นลายลักษณ์อักษรที่ยุติธรรม มีมาตรการจูงใจที่สมน้ำสมเนื้อ (เช่น เงินโบนัสพิเศษสำหรับการสกัดองค์ความรู้ หรือค่าที่ปรึกษาหลังเกษียณ) เพื่อป้องกันการฟ้องร้องและสร้างความรู้สึกเป็นส่วนหนึ่งของความสำเร็จ
- การรั่วไหลของข้อมูลความลับ: การนำข้อมูลความลับระดับสูงสุดของบริษัทไปป้อนเข้าสู่โมเดล AI สาธารณะ (Public LLMs) เช่น ChatGPT รุ่นฟรี ถือเป็นความเสี่ยงอย่างยิ่งยวด ดังนั้น องค์กรควรเลือกใช้ระบบ AI Workflow ที่ทำงานภายใต้คลาวด์ส่วนตัวขององค์กร (Enterprise Private Cloud / On-Premise deployment) ซึ่งรับประกันว่าข้อมูลจะไม่ถูกนำไปใช้ฝึกโมเดลสาธารณะเด็ดขาด
การหลีกเลี่ยงภาวะ AI Hallucination ในกระบวนการทำงานที่วิกฤต
โมเดลภาษายังคงมีโอกาสสร้างคำตอบที่ดูน่าเชื่อถือแต่ผิดพลาดทางเทคนิค (Hallucination) เพื่อแก้ปัญหานี้ในการผลิตจริง องค์กรต้องกำหนดมาตรการเชิงเทคนิคดังนี้:
- Strict RAG Guardrails: ตั้งค่า “Temperature” ของโมเดลให้ต่ำ (เข้าใกล้ 0.0) เพื่อลดความคิดสร้างสรรค์ของ AI และบังคับให้ตอบเฉพาะข้อมูลที่ระบุไว้ในคลังความรู้เท่านั้น
- No Source, No Answer: หากข้อมูลในคลังความรู้ไม่เพียงพอที่จะตอบคำถาม ให้กำหนดโปรโตคอลให้ AI ตอบว่า “ขออภัย ข้อมูลในฐานความรู้ของคุณสมชายไม่มีเนื้อหาเฉพาะส่วนนี้ กรุณาติดต่อวิศวกรซ่อมบำรุงที่ปฏิบัติหน้าที่แทน” แทนการพยายามประดิษฐ์คำตอบด้วยตัวเอง
อนาคตของการสืบทอดความรู้ด้วย AI: มุ่งสู่ Autonomous Enterprise
การสร้าง AI Workflow เพื่อสกัดความรู้จากผู้เชี่ยวชาญที่กำลังจะเกษียณอายุนั้น ไม่ใช่แค่การทำระบบเพื่อสู้กับวิกฤตชั่วคราว แต่เป็นอิฐบล็อกก้อนแรกในการเปลี่ยนผ่านองค์กรไปสู่ Autonomous Enterprise หรือองค์กรที่มีการดำเนินงานอัตโนมัติอัจฉริยะ
ในอนาคตอันใกล้ ระบบการจัดการความรู้จะไม่ใช่สิ่งที่ผู้ใช้ต้องเดินไปค้นหาอีกต่อไป แต่จะเป็นตัวกลางเชิงรุก (Proactive Knowledge Companion) ที่คอยเฝ้าสังเกตกระบวนการทำงานของพนักงานรุ่นใหม่ และเมื่อระบบตรวจพบว่าพนักงานกำลังดำเนินการด้วยวิธีที่ไม่มีประสิทธิภาพ หรือมีโอกาสเกิดความผิดพลาดสูง AI ที่รวบรวมองค์ความรู้จากผู้เชี่ยวชาญในอดีตทั้งหมดจะส่งสัญญาณแจ้งเตือนพร้อมแนะแนวทางแก้ไขที่ดีที่สุดให้ทันทีโดยไม่ต้องรอให้เอ่ยปากถาม
ด้วยการลงทุนสร้างระบบ AI Workflow ในวันนี้ องค์กรของคุณจะไม่เพียงแค่เอาตัวรอดจากภาวะสมองไหลของพนักงานรุ่นเก่าได้เท่านั้น แต่ยังเป็นการสร้างสินทรัพย์ทางปัญญาที่ไม่มีวันเสื่อมค่าและเติบโตไปพร้อมกับความก้าวหน้าทางเทคโนโลยีได้อย่างแท้จริง

บทสรุป (Conclusion)
การเกษียณอายุของพนักงานระดับผู้เชี่ยวชาญไม่ใช่จุดสิ้นสุดของขีดความสามารถขององค์กรอีกต่อไป หากแต่เป็นโอกาสสำคัญที่คุณจะได้ปฏิวัติระบบการจัดการความรู้ในแบบที่ไม่เคยทำได้มาก่อน ด้วยการออกแบบและสร้าง AI Workflow ที่ผสานรวมเทคโนโลยีระดับสูงอย่าง LLMs, RAG และ Multi-Agent Systems เข้าด้วยกัน คุณจะสามารถสกัด ถอดรหัส และแปลงประสบการณ์นับสิบ ๆ ปีให้กลายเป็นขุมทรัพย์สมองกลอันล้ำค่าที่พร้อมส่งต่อและสร้างประโยชน์ให้พนักงานรุ่นหลังได้ตลอด 24 ชั่วโมง
เริ่มต้นสร้าง AI Workflow ให้องค์กรของคุณตั้งแต่วันนี้ ก่อนที่ปัญญาและความเชี่ยวชาญอันล้ำค่าจะเดินออกประตูปีก่อนเกษียณไปอย่างน่าเสียดาย หากคุณยังไม่แน่ใจว่าจะเริ่มต้นอย่างไร ให้เลือกผู้เชี่ยวชาญที่มีกำหนดเกษียณในปีนี้เพียง 1 ท่าน แล้วเริ่มทำการบันทึกเสียงและสร้างโมเดลทดสอบ (Pilot Project) ทันที ผลลัพธ์ที่ได้จะสร้างความเปลี่ยนแปลงและเป็นพิมพ์เขียวสู่ความสำเร็จในอนาคตขององค์กรอย่างแน่นอน!
FAQ (คำถามที่พบบ่อย)
Q1: ควรเริ่มคุยและทำกระบวนการเก็บความรู้กับผู้เชี่ยวชาญล่วงหน้าก่อนเกษียณนานเท่าใด?
- คำตอบ: แนะนำให้เริ่มต้นอย่างน้อย 1 ปี ก่อนถึงกำหนดเกษียณอายุการทำงานจริง เนื่องจากการสกัดองค์ความรู้ (Knowledge Extraction) ให้ครอบคลุมทุกแง่มุมของการแก้ไขปัญหานั้นต้องใช้เวลาในการประมวลผล ตกผลึก และสร้างฐานข้อมูลความรู้ที่ครอบคลุมการเปลี่ยนแปลงในแต่ละไตรมาส นอกจากนี้ การทำล่วงหน้าจะช่วยให้ผู้เกษียณไม่เกิดความรู้สึกตึงเครียดหรือเร่งรีบจนเกินไป
Q2: พนักงานระดับผู้เชี่ยวชาญมักไม่เต็มใจแชร์ความรู้เพราะกลัวโดนลดความสำคัญลง จะแก้ปัญหานี้อย่างไร?
- คำตอบ: องค์กรต้องใช้วิธีเปลี่ยนมุมมองและมอบสิ่งตอบแทนที่เหมาะสม (Incentivization):
- ปรับภาพลักษณ์ของโครงการให้เป็นเกียรติยศ (Legacy Building) เพื่อเชิดชูคุณงามความดีและผลงานสะสมตลอดชีวิตการทำงานของพวกเขา
- จัดทำแพ็กเกจค่าตอบแทนพิเศษสำหรับการให้ความร่วมมือ เช่น “เงินรางวัลพิเศษเพื่อความสำเร็จของโครงการสืบทอดความรู้” (Knowledge Transfer Bonus)
- เสนอสัญญาจ้างเป็นที่ปรึกษาหลังเกษียณ (Post-retirement Consulting) แบบงานรายชั่วโมง เพื่อให้พวกเขารู้สึกมั่นคงทางการเงินและยังคงมีความสำคัญกับองค์กร
Q3: จำเป็นต้องจ้างโปรแกรมเมอร์เพื่อเขียนระบบ AI Workflow นี้จากศูนย์หรือไม่?
- คำตอบ: ในปี 2026 ไม่จำเป็นต้องเริ่มสร้างจากศูนย์เสมอไป ปัจจุบันมีแพลตฟอร์มประเภท No-code/Low-code AI Workflow Builder คุณภาพสูงมากมาย เช่น Dify.ai, Flowise, Make.com และ CrewAI Enterprise ที่ทำให้ผู้ดูแลระบบไอทีหรือวิศวกรทั่วไปสามารถสร้างและเชื่อมโยงโมเดลภาษาเข้ากับ Vector Database ได้อย่างรวดเร็ว เว้นแต่องค์กรที่มีข้อกำหนดความปลอดภัยของข้อมูลสูงสุดที่ต้องการสร้างโครงสร้างพื้นฐานเฉพาะของตัวเอง
Q4: หากผู้เชี่ยวชาญพูดภาษาไทยปนภาษาอังกฤษ หรือพูดไทยคำอังกฤษคำ AI Workflow สามารถจัดการได้ดีแค่ไหน?
- คำตอบ: โมเดลการแปลงเสียงเป็นข้อความและการวิเคราะห์ภาษา (Speech-to-Text & LLMs) ในยุคปี 2026 มีขีดความสามารถในการเข้าใจภาษารวม (Code-switching) เช่น ภาษาไทยคำอังกฤษคำ หรือศัพท์เฉพาะทางอุตสาหกรรม (Jargon) ได้อย่างมีประสิทธิภาพเกือบเทียบเท่ามนุษย์ ทั้งนี้ การทำความสะอาดข้อมูลดิบโดยการป้อนคำศัพท์เฉพาะที่พบบ่อย (Custom Dictionary) เข้าไปใน Prompt ของขั้นตอนการแปลงเสียงจะช่วยเพิ่มความแม่นยำขึ้นได้เกือบ 100%
Q5: จะมั่นใจได้อย่างไรว่า AI จะไม่ให้ข้อมูลที่เป็นอันตรายหรือผิดพลาดเมื่อพนักงานใหม่นำไปใช้?
- คำตอบ: สามารถสร้างความปลอดภัยได้ผ่านการกำหนด Strict Guardrails:
- จำกัดขอบเขตการตอบของ AI (Prompt Constraints) ห้ามมิให้คาดเดาข้อมูลภายนอกนอกเหนือจากเอกสารและเสียงสัมภาษณ์ที่มีอยู่ในฐานความรู้เท่านั้น
- ติดตั้งระบบกรองคำตอบ (Output Guardrails) เพื่อบล็อกการสร้างเนื้อหาที่ไม่เหมาะสมหรือคำแนะนำที่เป็นอันตรายทางเทคนิค
- ใช้ระบบตรวจทานโดยมนุษย์ (Human-in-the-loop) สำหรับการอนุญาตแก้ไขปัญหาในขั้นตอนสำคัญของกระบวนการผลิตเพื่อรับประกันความปลอดภัยสูงสุด
แหล่งอ้างอิงข้อมูล (References)
- World Economic Forum (WEF): The Future of Jobs Report 2024-2026. weforum.org
- Harvard Business Review: Managing Tacit Knowledge and Brain Drain in the Aging Workforce. hbr.org
- LlamaIndex Documentation: Advanced Retrieval-Augmented Generation (RAG) Architectures for Enterprise Data. llamaindex.ai
- Pinecone Vector Database: Semantic Search and Vector Embeddings Explained. pinecone.io