

ในเวลาที่มี AI โมเดลใหม่ ๆ ออกมา ผู้สร้างมักจะบอก AI parameters เป็นขนาดที่เราอ่านแล้วก็ไม่เข้าใจ เช่น : 70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, และ 12B. เป็นต้น แล้วขนาดเหล่านี้ คืออะไร ดี ไม่ดีอย่างไร แล้วผู้ใช้อย่างเรา ควรเลือกแบบใด หรือจ่ายค่าใช้งานแบบใด จึงจะดี .. บทความนี้ มีคำตอบ
ขนาดของพารามิเตอร์ใน LLM (Large Language Model) นั้นไม่ได้หมายถึงขนาดทางกายภาพ แต่หมายถึง จำนวนพารามิเตอร์ทั้งหมด ที่อยู่ในโมเดลนั้นเอง พารามิเตอร์เหล่านี้เปรียบเสมือนตัวแปรที่โมเดลจะเรียนรู้และปรับค่าให้เหมาะสมที่สุด เพื่อให้สามารถทำนายภาษาได้อย่างแม่นยำ

อย่างเช่นในตารางด้านล่างนี้ จะแสดงขนาด Parameter ต่าง ๆ ซึ่งถึงตอนนี้ หลาย ๆ คนคงเริ่มอยากรู้แล้วว่า ขนาดเหล่านี้ หมายถึงอะไรกันแน่
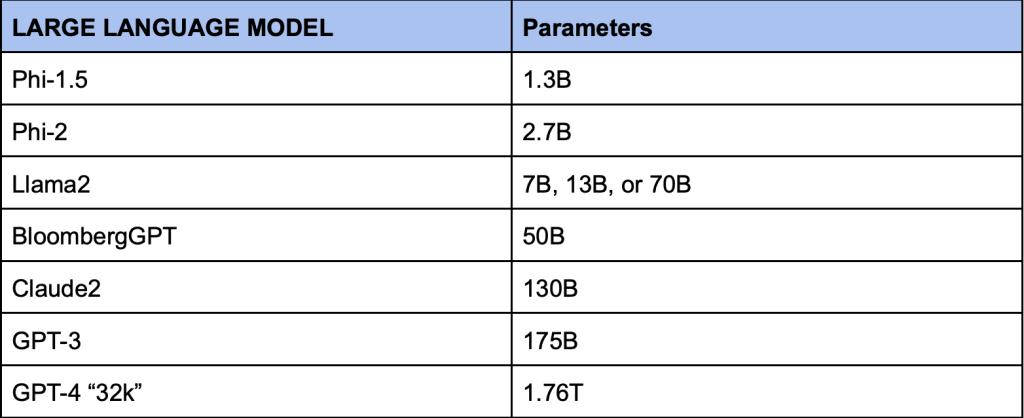
parameter ของ AI คืออะไร?
พารามิเตอร์ของ AI หรือ LLM (Large Language Model) นั้นเปรียบเสมือนปุ่มปรับแต่งเล็กๆ นับล้านที่อยู่ภายในโมเดลภาษาเหล่านี้ ซึ่งเป็นตัวเลขที่โมเดลเรียนรู้มาจากข้อมูลจำนวนมหาศาล เพื่อให้สามารถทำนายคำต่อไปในประโยคได้อย่างแม่นยำ และเข้าใจความหมายของภาษาได้อย่างลึกซึ้งยิ่งขึ้น ซึ่งจะเปรียบไปแล้ว พารามิเตอร์เหล่านี้ เปรียบเหมือนปริมาณความรู้และประสบการณ์ที่สมองกลเก็บสะสมมา
ความสำคัญของพารามิเตอร์มีอะไรบ้าง
- ความสามารถในการทำนาย: ยิ่งมีพารามิเตอร์มากขึ้น โมเดลก็ยิ่งสามารถทำนายคำต่อไปได้อย่างแม่นยำมากขึ้น ทำให้ข้อความที่สร้างขึ้นมีความเป็นธรรมชาติและสอดคล้องกันมากขึ้น
- ความเข้าใจภาษา: พารามิเตอร์ช่วยให้โมเดลเข้าใจความหมายของภาษาได้ลึกซึ้งยิ่งขึ้น สามารถตอบคำถามที่ซับซ้อน และแปลภาษาได้อย่างมีประสิทธิภาพ
- ความสามารถในการเรียนรู้: พารามิเตอร์สามารถปรับเปลี่ยนได้ตลอดเวลา ทำให้โมเดลสามารถเรียนรู้สิ่งใหม่ๆ และพัฒนาประสิทธิภาพได้อย่างต่อเนื่อง
- ความซับซ้อน: โมเดลที่มีพารามิเตอร์จำนวนมาก จะมีความซับซ้อนในการคำนวณมากขึ้น จึงต้องใช้ทรัพยากรในการประมวลผลที่สูงขึ้น
- ต้นทุน: การฝึกอบรมโมเดลที่มีพารามิเตอร์จำนวนมาก ต้องใช้เวลาและค่าใช้จ่ายในการคำนวณที่สูงมาก
- GPU : ขนาดยิ่งใหญ่ ยิ่งต้องใช้ทรัพยากรสูง การจะพัฒนาต่อยอด จึงต้องใช้งบประมาณสูงด้วยเช่นกัน
พารามิเตอร์ยิ่งมาก ยิ่งดี ใช่หรือไม่
ตอบได้ทันทีเลยว่า “อาจใช่” และไม่เสมอไป
ขนาดพารามิเตอร์ที่มาก ๆ อาจให้ผลดีในบางการใช้งาน แต่อาจไม่ดีเลยสำหรับงานบางประเภท
ยิ่ง LLM มีพารามิเตอร์มากเท่าใด “การตั้งค่า” ก็จะสามารถปรับได้มากขึ้นเพื่อจับความซับซ้อนของภาษามนุษย์ และด้วยเหตุนี้จึงประมวลผลภาษามนุษย์ได้ดีกว่าโมเดลที่มีพารามิเตอร์น้อยกว่า ดังนั้น หากโมเดล A และโมเดล B ต่างกันเพียงความสามารถในการประมวลผลและสร้างภาษา แน่นอนว่าเราควรเลือกโมเดลที่มีความสามารถในการประมวลผลภาษาที่เหนือกว่า
แต่ในโลกแห่งความจริง ยังมีอีกหลาย ๆ ปัจจัย ที่ควรพิจารณา เช่น ยิ่งโมเดลมีขนาดใหญ่เท่าใด ต้นทุน ค่าใช้จ่ายในการใช้งานก็จะยิ่งมากขึ้นเท่านั้น ทั้งกระบวนการฝึกอบรมโมเดลและการบำรุงรักษาอย่างต่อเนื่องต้องใช้พลังในการคำนวณและข้อมูลจำนวนมาก ด้วยเหตุนี้ LLM เช่น GPT-3 หรือ GPT-4 จึงมักได้รับการพัฒนาโดยองค์กรที่มีทรัพยากรจำนวนมาก
ผลกระทบจาก AI Parameter
การใช้โมเดลภาษาขนาดใหญ่อาจก็ก่อให้เกิดผลกระทบต่อสิ่งแวดล้อมได้เช่นกัน มีการศึกษาที่มหาวิทยาลัยแมสซาชูเซตส์ แอมเฮิร์สต์ พบว่าการฝึกแบบจำลองขนาดใหญ่ที่มีพารามิเตอร์ 213M สามารถสร้างการปล่อยก๊าซคาร์บอนไดออกไซด์ได้มากกว่า 626,000 ปอนด์ สำหรับการเปรียบเทียบ การปล่อยก๊าซตลอดอายุการใช้งานของรถยนต์อเมริกันโดยเฉลี่ย (รวมถึงการผลิตรถยนต์ด้วย) คือคาร์บอนไดออกไซด์ 126,000 ปอนด์ - ประมาณหนึ่งในห้าของการปล่อยก๊าซคาร์บอนที่เกิดจากการฝึกอบรม LLM ด้วยพารามิเตอร์ 213M! ยิ่งโมเดลมีขนาดใหญ่เท่าใด พลังงานก็จะยิ่งมากขึ้นเท่านั้น และยิ่งปล่อยก๊าซคาร์บอนตามมามากขึ้นด้วย โมเดลขนาดเล็กมีผลกระทบต่อสิ่งแวดล้อมน้อยกว่ามาก อย่างไรก็ตาม โมเดลที่ใหญ่กว่าซึ่งมีข้อมูลการฝึกคุณภาพต่ำกว่าไม่จำเป็นต้องมีประสิทธิภาพดีกว่าโมเดลที่เล็กกว่าซึ่งเน้นมากกว่าเสมอไป โมเดลที่มีพารามิเตอร์น้อยกว่าซึ่งได้รับการฝึกกับข้อมูลคุณภาพสูงจะมีประสิทธิภาพเหนือกว่าโมเดลขนาดใหญ่ที่ได้รับการฝึกกับข้อมูลคุณภาพต่ำ กล่าวอีกนัยหนึ่ง คุณภาพของข้อมูลที่ใช้ในการฝึกโมเดลมีความสำคัญพอๆ กับขนาดของโมเดลนั่นเอง






Leave a Reply