รากฐานสู่การวิวัฒน์ให้กับ LLM AI ความสำคัญของการจัดเก็บข้อมูลต่อการประมวลผลและปัญญาประดิษฐ์
การจัดเก็บข้อมูลเป็นรากฐานสำคัญของการประมวลผลคอมพิวเตอร์สมัยใหม่ ซึ่งช่วยให้สามารถบันทึก จัดเก็บ และประมวลผลข้อมูลดิจิทัลได้ การดำรงอยู่และความก้าวหน้าของระบบการประมวลผลที่ซับซ้อน รวมถึงปัญญาประดิษฐ์ (AI) ที่มีความซับซ้อนสูง ล้วนเชื่อมโยงอย่างแยกไม่ออกกับขีดความสามารถของเทคโนโลยีการจัดเก็บข้อมูล. ตลอดเส้นทางประวัติศาสตร์ของการพัฒนาเทคโนโลยี การแสวงหาประสิทธิภาพที่เพิ่มขึ้น ความจุที่ขยายใหญ่ขึ้น และการเข้าถึงข้อมูลที่ดียิ่งขึ้นในการจัดการข้อมูล ได้ทำหน้าที่เป็นแรงขับเคลื่อนหลัก. นวัตกรรมอย่างต่อเนื่องในการจัดเก็บข้อมูลนี้ได้ผลักดันขีดจำกัดของสิ่งที่สามารถประมวลผลได้ด้วยคอมพิวเตอร์อย่างสม่ำเสมอ
การพัฒนาในเทคโนโลยีการจัดเก็บข้อมูลมีความสัมพันธ์แบบพึ่งพาอาศัยกันกับการประมวลผลอย่างลึกซึ้ง ในช่วงแรกเริ่ม ระบบคอมพิวเตอร์ถูกจำกัดอย่างมากด้วยข้อจำกัดของกลไกการจัดเก็บข้อมูล เช่น บัตรเจาะรูที่ช้าและมีความจุน้อย. เมื่อหน่วยประมวลผลเร็วขึ้นและมีประสิทธิภาพมากขึ้น คอขวดของประสิทธิภาพระบบโดยรวมก็เปลี่ยนไปอยู่ที่หน่วยความจำและระบบจัดเก็บข้อมูลโดยตรง ซึ่งก่อให้เกิดความต้องการเร่งด่วนสำหรับโซลูชันการจัดเก็บข้อมูลที่เร็วขึ้นและมีความจุสูงขึ้น. เพื่อตอบสนองความต้องการนี้ นวัตกรรมอย่างเทปแม่เหล็กและหน่วยความจำคอร์แม่เหล็กจึงถือกำเนิดขึ้น ซึ่งให้ความเร็วและความจุที่จำเป็นในการปลดล็อกศักยภาพของหน่วยประมวลผลที่เร็วกว่า. สิ่งนี้แสดงให้เห็นถึงความสัมพันธ์แบบพึ่งพาอาศัยกันอย่างลึกซึ้ง: ความก้าวหน้าในพลังการประมวลผลจำเป็นต้องมีการก้าวกระโดดที่สอดคล้องกันในเทคโนโลยีการจัดเก็บข้อมูล และในทางกลับกัน ความสามารถในการจัดเก็บข้อมูลที่เหนือกว่าก็เปิดพรมแดนใหม่สำหรับความซับซ้อนของการประมวลผลและการประยุกต์ใช้ เช่น การพัฒนาโมเดล AI ขนาดใหญ่ เป็นวงจรนวัตกรรมที่เสริมสร้างซึ่งกันและกันอย่างต่อเนื่อง
ภาพรวมของวิวัฒนาการการจัดเก็บข้อมูลและบทบาทต่อ LLM AI
การเดินทางของเทคโนโลยีการจัดเก็บข้อมูล ตั้งแต่ระบบกลไกพื้นฐานไปจนถึงโซลิดสเตตที่ล้ำสมัยและเทคโนโลยีเกิดใหม่ที่กำลังพัฒนา ได้รับการกำหนดลักษณะด้วยการทำลายข้อจำกัดด้านข้อมูลอย่างต่อเนื่อง การพัฒนาที่สำคัญแต่ละครั้งได้ปูทางอย่างเป็นระบบสำหรับการถือกำเนิดและการทำงานที่ซับซ้อนของแอปพลิเคชันที่ต้องใช้ข้อมูลจำนวนมาก โดยเฉพาะอย่างยิ่ง Large Language Models (LLMs).
LLMs ซึ่งได้รับการออกแบบมาเพื่อทำความเข้าใจ ประมวลผล และสร้างข้อความที่คล้ายมนุษย์ ล้วนพึ่งพาความสามารถในการเข้าถึงและใช้ชุดข้อมูลขนาดมหึมาสำหรับการฝึกอบรมเริ่มต้นและการดำเนินการอนุมานในภายหลัง. ปริมาณข้อมูลที่มหาศาล ประเภทข้อมูลที่หลากหลาย และความเร็วในการเข้าถึงข้อมูลที่ LLMs ต้องการ ล้วนมีความสัมพันธ์โดยตรงกับ และถูกขับเคลื่อนโดย ความก้าวหน้าแบบทวีคูณในความจุ ความเร็วในการเข้าถึง และความคุ้มค่าของต้นทุนการจัดเก็บข้อมูลที่เกิดขึ้นตลอดหลายทศวรรษที่ผ่านมา.
วิวัฒนาการของการจัดเก็บข้อมูลคอมพิวเตอร์: จากบัตรเจาะรูสู่ SSD
ยุคบุกเบิก: การจัดเก็บข้อมูลเชิงกลและแม่เหล็กยุคแรก
บัตรเจาะรู: จุดเริ่มต้นของการบันทึกข้อมูล
บัตรเจาะรู ถือเป็น “รากฐานสู่การวิวัฒน์ให้กับ LLM AI” ซึ่่งเป็นสื่อกระดาษแข็งที่ใช้ในการจัดเก็บและประมวลผลข้อมูลดิจิทัลหรืออนาล็อกผ่านการมีอยู่หรือไม่มีอยู่ของรูในตำแหน่งที่กำหนดไว้ล่วงหน้า. หลักการทำงานของบัตรเจาะรูคือการแสดงข้อมูลผ่านการมีอยู่หรือไม่ของรูในตำแหน่งที่กำหนดไว้ล่วงหน้าบนกระดาษแข็ง ซึ่งทำหน้าที่เป็นรหัสไบนารีที่เครื่องสามารถอ่านได้. การใช้งานครั้งแรกสุดย้อนไปถึง Basile Bouchon ในปี 1725 ซึ่งเกี่ยวข้องกับการควบคุมเครื่องทอผ้าผ่านลำดับคำสั่ง. Charles Babbage ได้เสนอการใช้งานบัตรเจาะรูสำหรับคำสั่งและการตอบสนองใน Analytical Engine ของเขาในปี 1837 ซึ่งเป็นเครื่องคิดเลขเชิงกลแบบดั้งเดิม. Herman Hollerith ได้พัฒนาแนวคิดนี้อย่างมีนัยสำคัญ โดยใช้บัตรเจาะรูสำหรับการสำรวจสำมะโนประชากรสหรัฐฯ ปี 1890 เพื่อแสดงและจัดเก็บข้อมูลจริงที่เครื่องสามารถอ่านได้ ซึ่งวางรากฐานสำหรับการประมวลผลข้อมูลสมัยใหม่.
บัตรเจาะรู IBM 80 คอลัมน์ ซึ่งเปิดตัวในปี 1928 ได้กลายเป็นมาตรฐานอุตสาหกรรมอย่างรวดเร็ว โดยทำหน้าที่เป็นสื่อหลักสำหรับการป้อนข้อมูล การจัดเก็บ และแม้กระทั่งการเขียนโปรแกรมซอฟต์แวร์ตลอดศตวรรษที่ 20. แม้ว่าในที่สุดจะล้าสมัยโดยสื่อแม่เหล็กในช่วงทศวรรษ 1980 แต่บัตรเจาะรูได้ทิ้งมรดกที่ยั่งยืนไว้ โดยมีอิทธิพลต่อธรรมเนียมปฏิบัติ เช่น ความยาวบรรทัด 80 ตัวอักษรที่พบบ่อยในการแสดงผลคอมพิวเตอร์.
การทำงานของบัตรเจาะรูโดยพื้นฐานแล้วอาศัยหลักการไบนารี: รู (เปิด/1) หรือไม่มีรู (ปิด/0). การเข้ารหัสไบนารีที่เรียบง่ายนี้เป็นวิธีการที่แพร่หลายวิธีแรกสุดในการแสดงข้อมูลดิจิทัลในรูปแบบที่เครื่องสามารถอ่านได้ การสร้างมาตรฐานในภายหลัง โดยเฉพาะอย่างยิ่งกับบัตร IBM 80 คอลัมน์ ได้สร้างแนวคิดพื้นฐานของการจัดวางข้อมูลที่มีโครงสร้าง การนำเสนอไบนารีและการจัดรูปแบบมาตรฐานในยุคแรกนี้ได้วางรากฐานแนวคิดและการปฏิบัติสำหรับเทคโนโลยีการจัดเก็บข้อมูลดิจิทัลในภายหลังทั้งหมด รวมถึงข้อมูลบิตและไบต์ที่ประกอบกันเป็นชุดข้อมูลขนาดใหญ่ ทั้งที่มีโครงสร้างและไม่มีโครงสร้าง ซึ่งมีความสำคัญอย่างยิ่งต่อการฝึกอบรม LLM มันแสดงให้เห็นถึงพลังของการแยกข้อมูลออกเป็นรูปแบบที่เครื่องสามารถตีความได้
a Jacquard loom‘s chain, constructed using 8 × 26 hole punched cards รากฐานสู่การวิวัฒน์ให้กับ LLM AI
เทปแม่เหล็ก: ก้าวแรกสู่การจัดเก็บข้อมูลความเร็วสูง
รากฐานสู่การวิวัฒน์ให้กับ LLM AI ต่อมา คือ เทปแม่เหล็ก ซึ่งได้รับการจดสิทธิบัตรครั้งแรกโดย Fritz Pfleumer ในปี 1928 จัดเก็บข้อมูลดิจิทัลโดยการทำให้สารเคลือบบางๆ บนสื่อเทปเป็นแม่เหล็ก. เทปแม่เหล็กปรากฏเป็นการปรับปรุงที่สำคัญเหนือบัตรเจาะรู โดยค่อยๆ เข้ามาแทนที่ในฐานะวิธีการจัดเก็บข้อมูลหลักในช่วงทศวรรษ 1960 เนื่องจากมีความหนาแน่นสูงกว่าและเข้าถึงข้อมูลตามลำดับได้เร็วกว่า. การใช้งานเชิงพาณิชย์ครั้งแรกคือบน UNIVAC I ในปี 1951 โดยเริ่มแรกใช้เทปโลหะก่อนที่จะเปลี่ยนไปใช้เทปพลาสติกที่คุ้มค่ากว่าและเบากว่า. เครื่องขับเทปแบบคอลัมน์สุญญากาศของ IBM เช่น IBM 727 และ 729 (ทศวรรษ 1950-60) เป็นความสำเร็จทางวิศวกรรมที่ใช้ลูปเทปรูปตัว U ที่มีบัฟเฟอร์สุญญากาศ เพื่อให้สามารถเริ่มและหยุดได้อย่างรวดเร็วโดยไม่ทำให้เทปเสียหาย.
รูปแบบเทป 7 แทร็กและ 9 แทร็กของ IBM ได้กลายเป็นมาตรฐานอุตสาหกรรมโดยพฤตินัย ซึ่งช่วยเพิ่มความเร็วในการประมวลผลข้อมูลได้อย่างมาก ภายในปี 1964 เครื่องขับเทป IBM System/360 สามารถประมวลผลได้ 90,000 ตัวอักษรต่อวินาที และเริ่ม/หยุดได้ในเวลาเพียง 0.0015 วินาที. รีลเทปยุคแรกสามารถเก็บข้อมูลได้มากกว่าหนึ่งล้านตัวอักษร (IBM 701, 1952) และพัฒนาไปถึง 175MB ต่อเทปสำหรับระบบ IBM 9 แทร็ก. เทปแม่เหล็กยังคงเป็นสื่อหลักสำหรับการจัดเก็บข้อมูลแบบออฟไลน์และการถ่ายโอนข้อมูลมานานกว่าสามทศวรรษ. แม้ว่าจะถูกแทนที่ด้วยเทคโนโลยีการเข้าถึงแบบสุ่มที่เร็วกว่าสำหรับการจัดเก็บข้อมูลหลัก แต่เทปแม่เหล็กยังคงเป็นโซลูชันที่ใช้งานได้จริง คุ้มค่า ปรับขนาดได้ และทนทานสำหรับการสำรองข้อมูลและการเก็บถาวรระยะยาวในศูนย์ข้อมูลสมัยใหม่.
บัตรเจาะรูต้องการการจัดการด้วยตนเองอย่างมากสำหรับการป้อนข้อมูล การจัดเรียง และการประมวลผล. เทปแม่เหล็ก ด้วยรีลที่ต่อเนื่องและเครื่องขับเทปอัตโนมัติ ได้ลดแรงงานคนในการประมวลผลข้อมูลลงอย่างมาก. สิ่งนี้ถือเป็นก้าวสำคัญสู่ระบบจัดการข้อมูลอัตโนมัติเต็มรูปแบบ นอกจากนี้ บทบาทของเทปในฐานะสื่อที่มีความจุสูง ค่อนข้างช้า และราคาไม่แพง ได้ตอกย้ำแนวคิดของ “การจัดเก็บแบบออฟไลน์” ที่แตกต่างจากหน่วยความจำ “ออนไลน์” ที่เร็วกว่าและมีราคาแพงกว่า สิ่งนี้ได้สร้างมุมมองลำดับชั้นของการจัดเก็บข้อมูลที่สำคัญในยุคแรก (ข้อมูลร้อนเทียบกับข้อมูลเย็น, หลักเทียบกับรอง/สำรอง) ซึ่งยังคงเป็นพื้นฐานในสถาปัตยกรรมข้อมูลสมัยใหม่ รวมถึงที่รองรับ LLM ซึ่งชุดข้อมูลขนาดใหญ่อาจอยู่ในระดับการจัดเก็บถาวรที่ช้ากว่าและถูกกว่า ก่อนที่จะถูกย้ายไปยังที่จัดเก็บที่เร็วกว่าสำหรับการฝึกอบรมที่ใช้งานอยู่

ดรัมแม่เหล็กและหน่วยความจำคอร์: การเข้าถึงข้อมูลแบบสุ่ม
ดรัมแม่เหล็ก: ดรัมแม่เหล็กถูกคิดค้นโดย Gustav Taushek ในปี 1932 โดยเป็นกระบอกโลหะขนาดใหญ่ที่เคลือบด้วยวัสดุบันทึกข้อมูลแม่เหล็ก. ข้อมูลถูกเขียนและอ่านโดยหัวอ่าน/เขียนแบบตายตัวที่วางอยู่ตามพื้นผิวของดรัม การเข้าถึงข้อมูลเกี่ยวข้องกับการรอให้ข้อมูลที่ต้องการหมุนมาอยู่ใต้หัวอ่าน/เขียนที่กำหนด (ความหน่วงในการหมุน). ดรัมแม่เหล็กถูกนำมาใช้กันอย่างแพร่หลายเป็นหน่วยความจำคอมพิวเตอร์ในช่วงทศวรรษ 1950 และ 1960. IBM 650 (1954) ซึ่งเป็นหนึ่งในคอมพิวเตอร์ที่ผลิตจำนวนมากเครื่องแรก ได้ใช้หน่วยความจำดรัมอย่างกว้างขวาง โดยเริ่มแรกให้พื้นที่จัดเก็บประมาณ 8.5 กิโลไบต์. ดรัมแม่เหล็กทำหน้าที่เป็นต้นกำเนิดของฮาร์ดดิสก์ไดรฟ์ในหลักการบันทึกข้อมูลแบบแม่เหล็ก.
หน่วยความจำคอร์แม่เหล็ก: หน่วยความจำคอร์แม่เหล็กพัฒนาขึ้นในช่วงปลายทศวรรษ 1940 โดยปฏิวัติหน่วยความจำคอมพิวเตอร์โดยใช้แกนเฟอร์ไรต์รูปโดนัทขนาดเล็ก ซึ่งแต่ละอันแสดงถึงบิตไบนารีเดียว (0 หรือ 1) ตามการโพลาไรซ์แม่เหล็ก. แกนเหล่านี้ถูกร้อยด้วยสายไฟที่ตัดกันซึ่งสามารถตรวจจับและเปลี่ยนสถานะแม่เหล็กได้ ทำให้สามารถเข้าถึงบิตที่จัดเก็บไว้แบบสุ่มได้อย่างแท้จริง. คอมพิวเตอร์ Whirlwind ของ MIT (1953) เป็นระบบบุกเบิกที่รวมเทคโนโลยีนี้เข้าด้วยกัน.
หน่วยความจำคอร์แม่เหล็กได้รับความนิยมอย่างรวดเร็วเนื่องจากความเร็วและประสิทธิภาพที่เหนือกว่าเมื่อเทียบกับบัตรเจาะรู. ความเร็วในการทำงานเพิ่มขึ้นอย่างมีนัยสำคัญ จาก 200 kHz เริ่มต้นเป็นมากกว่า 1 MHz และระนาบหน่วยความจำคอร์ 32×32 ทั่วไปสามารถจัดเก็บข้อมูลได้ 1024 บิต (128 ไบต์). แม้จะมีกระบวนการผลิตที่ต้องใช้แรงงานมากและละเอียดอ่อน แต่หน่วยความจำคอร์แม่เหล็กก็กลายเป็นเทคโนโลยีหน่วยความจำหลักที่โดดเด่นสำหรับคอมพิวเตอร์ยุคแรกมานานกว่าทศวรรษ ซึ่งพิสูจน์แล้วว่ามีความสำคัญอย่างยิ่งต่อการพัฒนาระบบคอมพิวเตอร์ที่ซับซ้อนและโต้ตอบได้มากขึ้น.
วิธีการจัดเก็บข้อมูลก่อนหน้านี้ เช่น บัตรเจาะรูและเทปแม่เหล็ก ส่วนใหญ่เสนอการเข้าถึงแบบตามลำดับ ซึ่งต้องอ่านข้อมูลตามลำดับ. ดรัมแม่เหล็ก และที่สำคัญกว่านั้นคือหน่วยความจำคอร์แม่เหล็ก ได้นำเสนอความสามารถในการเข้าถึงแบบสุ่ม ซึ่งหมายความว่าข้อมูลใดๆ ก็สามารถเรียกใช้หรือแก้ไขได้โดยตรงโดยไม่ต้องผ่านข้อมูลก่อนหน้า. ความสามารถที่ปฏิวัติวงการนี้ได้เปลี่ยนแปลงกระบวนทัศน์การประมวลผลคอมพิวเตอร์โดยพื้นฐาน ทำให้สามารถพัฒนาระบบปฏิบัติการที่ซับซ้อนยิ่งขึ้น การประมวลผลแบบเรียลไทม์ และระบบจัดการฐานข้อมูลที่อาศัยการเรียกใช้ข้อมูลแบบไม่ตามลำดับ สำหรับ AI สมัยใหม่ โดยเฉพาะ LLM การเข้าถึงแบบสุ่มเป็นสิ่งจำเป็นสำหรับการฝึกอบรมที่มีประสิทธิภาพ โดยที่โมเดลจะเข้าถึงจุดข้อมูลที่แตกต่างกันซ้ำๆ ในรูปแบบที่ไม่เป็นเชิงเส้นระหว่างกระบวนการปรับปรุงแบบวนซ้ำ
หน่วยความจำคอร์แม่เหล็กให้ความเร็วที่เหนือกว่าเมื่อเทียบกับรุ่นก่อนหน้า แต่เป็นที่รู้กันว่าผลิตได้ยากและใช้เวลานาน ซึ่งต้องใช้แรงงานคนที่มีความละเอียดอ่อน. ความซับซ้อนโดยธรรมชาติของสิ่งนี้ทำให้ต้นทุนสูง แม้จะมีข้อได้เปรียบด้านประสิทธิภาพก็ตาม สิ่งนี้เน้นย้ำถึงประเด็นที่ยั่งยืนในวิวัฒนาการของการจัดเก็บข้อมูล: ความตึงเครียดและการแลกเปลี่ยนอย่างต่อเนื่องระหว่างการบรรลุประสิทธิภาพที่สูงขึ้น (ความเร็ว ความหนาแน่น) การจัดการความซับซ้อนในการผลิต และการควบคุมต้นทุน เทคโนโลยีที่นำเสนอการก้าวกระโดดด้านประสิทธิภาพที่สำคัญมักมาพร้อมกับค่าใช้จ่ายเริ่มต้นที่สูงหรือความท้าทายในการผลิต การนำไปใช้ในวงกว้างมักขึ้นอยู่กับนวัตกรรมที่ลดอุปสรรคเหล่านี้ พลวัตนี้ยังคงมีอิทธิพลต่อการนำเทคโนโลยีการจัดเก็บข้อมูลใหม่ๆ มาใช้สำหรับ AI ซึ่งโซลูชันประสิทธิภาพสูง (เช่น SSD เฉพาะทาง) ต้องได้รับการปรับสมดุลกับต้นทุนสำหรับการปรับใช้ขนาดใหญ่ระดับเพตะไบต์


ฮาร์ดดิสก์ไดรฟ์ (HDDs): รากฐานสู่การวิวัฒน์ให้กับ LLM AI การจัดเก็บข้อมูลทุติยภูมิมาตรฐาน
ฮาร์ดดิสก์ไดรฟ์ (HDDs) จัดเก็บข้อมูลดิจิทัลบนจานแม่เหล็กที่หมุนอย่างรวดเร็ว โดยมีหัวอ่าน/เขียนที่ “บิน” บนชั้นอากาศบางๆ เพียงไม่กี่ไมโครเมตรเหนือพื้นผิวจาน. HDDs เปิดตัวโดย IBM ในปี 1956 ด้วยระบบ IBM 350 RAMAC ได้สร้างระดับใหม่ในลำดับชั้นข้อมูลคอมพิวเตอร์ ซึ่งรู้จักกันในชื่อการจัดเก็บข้อมูลทุติยภูมิ ระดับนี้มีราคาถูกกว่าและช้ากว่าหน่วยความจำหลัก (เช่น หน่วยความจำคอร์แม่เหล็กหรือดรัม) แต่เร็วกว่าและแพงกว่าเครื่องขับเทปแม่เหล็กอย่างมาก.
นวัตกรรมที่สำคัญของ HDDs รวมถึงการนำหัวอ่าน/เขียนแบบบินได้เองด้วยอากาศพลศาสตร์มาใช้ และการนำ Error Correction มาใช้ในปี 1970 ซึ่งช่วยเพิ่มความน่าเชื่อถือและลดต้นทุนโดยการอนุญาตให้มีข้อบกพร่องเล็กน้อยบนพื้นผิวจาน. ในปี 1973 IBM ได้เปิดตัว “Winchester” ซึ่งเป็น HDD ที่มีการใช้หัวอ่าน/เขียนที่มีมวลต่ำและแรงกดต่ำพร้อมจานที่หล่อลื่นเป็นครั้งแรกในเชิงพาณิชย์อย่างมีนัยสำคัญ เทคโนโลยีนี้และอนุพันธ์ของมันยังคงเป็นมาตรฐานจนถึงปี 2011. นอกจากนี้ ในปี 1975 IBM และ StorageTek ได้นำเสนอ Swinging Arm Actuator ซึ่งกลายเป็นมาตรฐานสำหรับ HDDs ทั้งหมดในช่วงทศวรรษ 1980 และยังคงใช้งานอยู่ในปัจจุบัน.
วิวัฒนาการด้านความจุ ความเร็ว และต้นทุน รากฐานสู่การวิวัฒน์ให้กับ LLM AI : การใช้งาน HDD เชิงพาณิชย์เริ่มขึ้นในปี 1957 ด้วยระบบ IBM 305 RAMAC ซึ่งรวมถึง IBM Model 350 disk storage. IBM 350 มีจานขนาด 24 นิ้ว 50 แผ่น มีความจุรวม 5 ล้านตัวอักษร 6 บิต (3.75 เมกะไบต์). กลไกหัวอ่าน/เขียนเดียวให้เวลาเข้าถึงเฉลี่ยไม่ถึง 1 วินาที.
ความจุของฮาร์ดไดรฟ์เติบโตแบบทวีคูณเมื่อเวลาผ่านไป. เมื่อฮาร์ดไดรฟ์พร้อมใช้งานสำหรับคอมพิวเตอร์ส่วนบุคคล ฮาร์ดไดรฟ์มีความจุ 5 เมกะไบต์. ในช่วงกลางทศวรรษ 1990 ฮาร์ดดิสก์ไดรฟ์ทั่วไปสำหรับพีซีมีความจุในช่วง 500 เมกะไบต์ถึง 1 กิกะไบต์. ณ เดือนกุมภาพันธ์ 2025 ฮาร์ดดิสก์ไดรฟ์ที่มีความจุสูงถึง 36 TB ก็มีวางจำหน่ายแล้ว.
ตารางที่ 1: วิวัฒนาการความจุของฮาร์ดดิสก์ไดรฟ์ (HDDs) รากฐานสู่การวิวัฒน์ให้กับ LLM AI
| ปี | ชื่อ/รุ่น HDD | ความจุ (โดยประมาณ) |
| 1957 | IBM 350 (RAMAC) | 3.75 MB |
| 1961 | Bryant 4000 series | 205 MB |
| 1962 | IBM 1311 (Removable Disk Pack) | 2 MB |
| 1964 | IBM 2311 | 7.25 MB |
| 1970 | IBM 3330 “Merlin” | 100 MB |
| 1973 | IBM 3340 “Winchester” | 35 MB หรือ 70 MB |
| 1979 | IBM 0680 “Piccolo” (8-inch) | 64.5 MB |
| 1980 | IBM 3380 | 2.52 GB |
| 1980 | Seagate ST-506 (5.25-inch) | 5 MB |
| 1983 | Rodime RO351/RO352 (3.5-inch) | 10 MB |
| 1988 | PrairieTek 220 (2.5-inch) | 20 MB |
| 1991 | IBM 0663 “Corsair” | 1 GB |
| 1997 | IBM Deskstar 16 GB “Titan” | 16.8 GB |
| 1999 | IBM Microdrive (1-inch) | 170 MB & 340 MB |
| 2007 | Hitachi Deskstar 7K1000 | 1 TB |
| 2009 | Western Digital (2.5-inch) | 1 TB |
| 2013 | Helium-Filled HDDs (HGST) | สูงสุด 6 TB |
| 2021 | Seagate HAMR Drives | 20 TB |
| 2024 | Seagate Exos Mozaic 3+ | 32 TB |
| 2025 | Seagate Exos Mozaic 3+ (อัปเกรด) | 36 TB |
| ที่มา: |
ในด้านความเร็ว HDD ได้เห็นการปรับปรุงอย่างมาก: เวลาเข้าถึงของ Bryant 4000 series (1961) อยู่ที่ 50 ถึง 205 มิลลิวินาที (ms). Seagate ได้จัดส่งฮาร์ดไดรฟ์ 7,200-rpm ตัวแรกในปี 1992 (Barracuda) และ 10,000-rpm ตัวแรกในปี 1996 (Cheetah) ตามด้วย 15,000-rpm ตัวแรกในปี 2000 (Cheetah X15). ในปี 2017 Seagate อ้างว่าสามารถถ่ายโอนข้อมูลได้ 480 MB/s จากฮาร์ดไดรฟ์ 7200 rpm ทั่วไปโดยใช้แขนขับเคลื่อนอิสระสองแขน.
สำหรับต้นทุน ฮาร์ดดิสก์ไดรฟ์ในยุคแรกเริ่มมีราคาแพงมากสำหรับคอมพิวเตอร์ส่วนบุคคล. ในปี 1980 ฮาร์ดไดรฟ์ 5 เมกะไบต์ ขนาด 5.25 นิ้ว มีราคา 1,500 ดอลลาร์สหรัฐฯ. IBM 3380 ขนาด 2.52 GB ในปี 1980 มีน้ำหนัก 455 กก. และมีราคา 81,000 ดอลลาร์สหรัฐฯ (เทียบเท่า 309,115 ดอลลาร์สหรัฐฯ ในปัจจุบัน). อย่างไรก็ตาม ต้นทุนต่อ GB ได้ลดลงอย่างมาก จาก 109,000,000 ดอลลาร์สหรัฐฯ/GB ในปี 1956 เหลือเพียง 0.031 ดอลลาร์สหรัฐฯ/GB ในปี 2025. การลดลงของต้นทุนนี้ทำให้ SSDs เริ่มแข่งขันกับ HDDs ในด้านความจุที่ผู้บริโภคส่วนใหญ่ใช้ในปี 2020.

1956: First commercial hard disk drive shipped
ฟลอปปี้ดิสก์: สื่อจัดเก็บข้อมูลแบบถอดได้ที่แพร่หลาย
ฟลอปปี้ดิสก์เป็นสื่อจัดเก็บข้อมูลแบบถอดได้ที่ได้รับความนิยมอย่างแพร่หลาย ซึ่งก็ถือได้ว่าเป็นจุดเริ่ม รากฐานสู่การวิวัฒน์ให้กับ LLM AI โดยเข้ามาแทนที่บัตรเจาะรูในหลายแอปพลิเคชัน. ฟลอปปี้ดิสก์ขนาด 8 นิ้ว เปิดตัวโดย IBM ในปี 1971 โดยมีความจุเริ่มต้น 30KB และสามารถแทนที่บัตรเจาะรูได้ประมาณ 3000 ใบ. ต่อมามีการพัฒนาความจุที่ใหญ่ขึ้นเป็น 500KB แบบ Double Sided Single Density.
ฟลอปปี้ดิสก์ขนาด 5.25 นิ้ว พัฒนาขึ้นในปี 1976 และกลายเป็นทางเลือกที่ถูกกว่าและเล็กกว่าสำหรับฟลอปปี้ดิสก์ขนาด 8 นิ้วอย่างรวดเร็ว. มีความจุหลายระดับตั้งแต่ 160 KB (Single-sided, 8 sectors/track) ไปจนถึง 1.2 MB (High-Density). ฟลอปปี้ดิสก์ขนาด 3.5 นิ้ว ซึ่งเปิดตัวในปี 1984 โดย IBM เป็นฟอร์แมตฟลอปปี้ดิสก์ที่ผลิตจำนวนมากเป็นครั้งสุดท้าย และกลายเป็นมาตรฐานที่แพร่หลายที่สุด โดยมีความทนทานมากกว่าเนื่องจากบรรจุภัณฑ์พลาสติกแข็งที่มีชัตเตอร์โลหะเลื่อนได้. ฟลอปปี้ดิสก์ขนาด 3.5 นิ้วสามารถเก็บข้อมูลได้ 1.44MB และครองตลาดการจัดเก็บข้อมูลแบบถอดได้มานานหลายทศวรรษ.
ฟลอปปี้ดิสก์มีบทบาทสำคัญในการปฏิวัติคอมพิวเตอร์ส่วนบุคคลและการเกิดขึ้นของอุตสาหกรรมซอฟต์แวร์อิสระ. ก่อนหน้าฟลอปปี้ดิสก์ ซอฟต์แวร์ส่วนใหญ่ถูกเขียนโดยเจ้าของพีซีเอง การมาถึงของฟลอปปี้ดิสก์ทำให้บริษัทซอฟต์แวร์สามารถเขียนโปรแกรม บันทึกลงดิสก์ และขายผ่านทางไปรษณีย์หรือในร้านค้าได้. การพัฒนาความจุและขนาดที่เล็กลงอย่างต่อเนื่องของฟลอปปี้ดิสก์นี้สะท้อนให้เห็นถึงความพยายามในการทำให้การจัดเก็บข้อมูลเข้าถึงได้ง่ายขึ้นและพกพาได้มากขึ้น ซึ่งเป็นปัจจัยสำคัญที่ขับเคลื่อนการเติบโตของคอมพิวเตอร์ส่วนบุคคล

ฟลอปปี้ดิสก์ รากฐานสู่การวิวัฒน์ให้กับ LLM AI ที่ครั้งหนึ่ง เคยเป็นหนึ่ง
แผ่นดิสก์ออปติคัล (CD, DVD, Blu-ray): การจัดเก็บข้อมูลด้วยแสง
เทคโนโลยีการจัดเก็บข้อมูลด้วยแสงได้นำเสนอวิธีการใหม่ในการบันทึกและเรียกใช้ข้อมูลโดยใช้เลเซอร์และคุณสมบัติทางแสง แผ่นดิสก์คอมแพค (CD) ซึ่งผลิตโดย Phillips และ Sony ในปี 1982 เริ่มแรกออกแบบมาสำหรับการจัดเก็บและเล่นเสียง. CD เริ่มแรกมีเส้นผ่านศูนย์กลาง 120 มม. และสามารถเก็บเสียงสเตอริโอที่ไม่ได้บีบอัดได้ 74 นาที หรือข้อมูลประมาณ 650 MB. ต่อมาได้ขยายเป็น 80 นาทีและ 700 MB. รูปแบบนี้ได้รับการปรับให้เข้ากับ CD-ROM, CD-R (เขียนครั้งเดียว) และ CD-RW (เขียนซ้ำได้). ภายในปี 2007 มีการขาย CD ทั่วโลกประมาณ 2 แสนล้านแผ่น.
ดิจิทัลวิดีโอดิสก์ (DVD) พัฒนาขึ้นในปี 1995 เพื่อให้มีความจุข้อมูลมากกว่า CD. DVD สามารถเก็บข้อมูลได้ 4.7 GB ซึ่งมากกว่า CD ถึงหกเท่า (700 MB). บางบริษัทได้พัฒนา DVD แบบหลายชั้นที่สามารถเก็บข้อมูลได้มากถึง 17.08 GB (สองด้าน สองชั้น). PlayStation 2 เป็นเครื่องเล่นวิดีโอเกมเครื่องแรกที่ใช้ DVD.
แผ่นดิสก์ออปติคัล Blu-ray เปิดตัวในปี 2003 โดย Blu-ray Disc Association เพื่อมาแทนที่ DVD และจัดเก็บวิดีโอความละเอียดสูง (720p และ 1080p). Blu-ray มีขนาดเท่ากับ CD และ DVD แต่ใช้เลเซอร์สีน้ำเงิน-ม่วง (405 nm) แทนเลเซอร์สีแดงหรืออินฟราเรด ซึ่งช่วยให้สามารถโฟกัสแสงไปที่จุดที่เล็กลงได้ ทำให้สามารถจัดเก็บข้อมูลได้หนาแน่นขึ้น. Blu-ray สามารถเก็บข้อมูลได้ตั้งแต่ 25 GB (ชั้นเดียว) ถึง 128 GB (รูปแบบ BDXL). ปัจจุบันยังคงใช้สำหรับการจัดจำหน่ายภาพยนตร์และวิดีโอเกมสำหรับ PlayStation และ Xbox. การพัฒนาแผ่นดิสก์ออปติคัลแสดงให้เห็นถึงความก้าวหน้าอย่างต่อเนื่องในการเพิ่มความหนาแน่นของการจัดเก็บข้อมูลโดยการใช้ความยาวคลื่นเลเซอร์ที่สั้นลงและเทคนิคการเข้ารหัสที่ดีขึ้น ซึ่งเป็นสิ่งสำคัญสำหรับการจัดเก็บเนื้อหามัลติมีเดียที่มีคุณภาพสูงขึ้น

แผ่นดิสก์ออปติคัล (CD, DVD, Blu-ray) วิวัฒน์สุ่ ความเป็นไปได้ ของ รากฐานสู่การวิวัฒน์ให้กับ LLM AI
ยุคหน่วยความจำแฟลชและโซลิดสเตตไดรฟ์ (SSDs): ความเร็วและความทนทาน
หน่วยความจำแฟลช: การจัดเก็บข้อมูลแบบไม่ระเหยขนาดเล็ก
หน่วยความจำประเภทนี้ ต้องบอกว่าเป็นก้าวสำคัญของการเป็น “รากฐานสู่การวิวัฒน์ให้กับ LLM AI” อย่างแท้จริง เพราะอะไร?
หน่วยความจำแฟลชเป็นเทคโนโลยีการจัดเก็บข้อมูลแบบไม่ระเหยที่ปฏิวัติวงการ โดยเก็บข้อมูลโดยการดักจับอิเล็กตรอนในเซลล์หน่วยความจำแบบ floating gates เพื่อแสดงข้อมูลไบนารี. Fujio Masuoka วิศวกรชาวญี่ปุ่นที่ Toshiba เป็นผู้คิดค้นหน่วยความจำแฟลชในปี 1980 ซึ่งเป็นรากฐานสำหรับ SSDs สมัยใหม่. คำว่า “แฟลช” ถูกเสนอโดย Shoji Ariizumi เพื่อนร่วมงานของ Masuoka เนื่องจากกระบวนการลบข้อมูลทำให้เขานึกถึงแสงแฟลชของกล้อง.
อุปกรณ์หน่วยความจำแฟลชได้พัฒนาไปสู่รูปแบบที่หลากหลายและแพร่หลาย:
- USB Flash Drive (1999): เป็นหนึ่งในอุปกรณ์จัดเก็บข้อมูลแบบพกพาที่สะดวกที่สุด. รุ่นแรก (1.0 และ 1.1) สามารถเก็บข้อมูลได้สูงสุด 8 MB. ปัจจุบันมีจำหน่ายสูงสุดถึง 2 TB ด้วยมาตรฐาน 3.1 ซึ่งเร็วกว่า 2.0 ถึง 5 เท่า.
- CF cards (Compact Flash) (1994): ผลิตโดย SanDisk สำหรับอุปกรณ์พกพา เช่น กล้องดิจิทัล เพื่อบันทึกเสียงและวิดีโอ. มีความจุสูงสุด 8 GB ในช่วงที่ได้รับความนิยม.
- SD Card (Secure Digital) (1999): การ์ดหน่วยความจำแบบไม่ระเหยที่พัฒนาโดย SD Association (SDA). การ์ดรุ่นแรก (1999-2002) มีความจุตั้งแต่ 32 MB ถึง 64 MB.
- MicroSD card (2005): สร้างโดย SanDisk ให้เป็น SD card ขนาดเล็กกว่า. มีความจุขยายได้ถึง 128 MB ในยุคแรก และปัจจุบันสามารถมีความจุมากกว่า 30 GB ในการ์ดเดียว. Motorola E395 เป็นโทรศัพท์เครื่องแรกที่ใช้ microSD card.
- CFast cards (2008): อิงตามอินเทอร์เฟซ Serial (SATA) ทำให้มีความเร็วเท่ากับพอร์ต SATA (สูงสุด 600 MBps สำหรับ SATA III). ปัจจุบันสามารถจัดการข้อมูลได้มากกว่า 128 GB ในการ์ดเดียว และใช้ในกล้อง เครื่องบันทึกเสียงและวิดีโอ.
- XQD card (2012): พัฒนาโดย Sony corporation แสดงความเร็วในการอ่านและเขียน 8 Gbit/s เมื่อทดสอบ และเป็นหนึ่งในการ์ดที่เร็วที่สุดในขณะนั้นเนื่องจากอินเทอร์เฟซการถ่ายโอนข้อมูล PCI express.
- CFexpress cards (2016): มาตรฐาน CF ใหม่ที่อิงตาม PCIe 3.0 และ NVME โดยรุ่น 1.0 (2017) มีความเร็วสูงสุด 2 Gbps และรุ่น 2.0 (2019) สูงสุด 4 Gbps. ปัจจุบันมีจำหน่ายในความจุ 512 GB และใช้ในการบันทึกเสียงและวิดีโอ.
การพัฒนาหน่วยความจำแฟลชได้เปลี่ยนวิธีการจัดเก็บข้อมูลแบบพกพาอย่างสิ้นเชิง ทำให้เกิดอุปกรณ์ที่เล็กกว่า ทนทานกว่า และเข้าถึงได้เร็วกว่า ซึ่งเป็นสิ่งสำคัญสำหรับการเติบโตของอุปกรณ์อิเล็กทรอนิกส์สำหรับผู้บริโภคและแอปพลิเคชันที่ต้องการการจัดเก็บข้อมูลแบบไม่ระเหยที่มีประสิทธิภาพ

2018 was a busy year for consumer SSDs.
โซลิดสเตตไดรฟ์ (SSDs): ประสิทธิภาพสูงสำหรับการประมวลผลสมัยใหม่ อย่าง AI
โซลิดสเตตไดรฟ์ (SSDs) เป็นอุปกรณ์จัดเก็บข้อมูลแบบโซลิดสเตตที่ใช้วงจรรวมในการจัดเก็บข้อมูลอย่างถาวร. แตกต่างจาก HDDs และฟลอปปี้ดิสก์ SSDs ไม่มีจานหมุนหรือหัวอ่าน/เขียนที่เคลื่อนที่ได้ ทำให้มีความเร็วในการเข้าถึงข้อมูลที่เร็วกว่า ใช้พลังงานต่ำกว่า และออกแบบมาให้ทนทานกว่า.
ต้นกำเนิดของ SSDs ย้อนไปถึงทศวรรษ 1950 ด้วยเทคโนโลยีหน่วยความจำคอร์แม่เหล็กและ card capacitor read-only store. SSDs ตัวแรกถูกสร้างขึ้นในปี 1976 โดย Dataram Corporation ชื่อ “Bulk Core” ซึ่งให้พื้นที่จัดเก็บ 2MB และมีราคา 9,700 ดอลลาร์สหรัฐฯ (เทียบเท่า 36,317 ดอลลาร์สหรัฐฯ ในปัจจุบัน). ในปี 1991 SanDisk ได้นำ SSD ที่ใช้แฟลชตัวแรกมาใช้ในซูเปอร์คอมพิวเตอร์ IBM, Amdahl และ Cray ซึ่งสามารถเก็บข้อมูลได้ 20 MB. ประมาณปี 2007 Fusion-io ได้ประกาศ PCIe-based SSD ตัวแรก. ปัจจุบัน SSD สำหรับผู้บริโภคมีจำหน่ายในความจุ 8TB และ SSD ระดับองค์กรสามารถมีความจุสูงถึง 122.88TB ในปี 2025.
ตลอดหลายปีที่ผ่านมา เทคโนโลยี SSD ได้รับการปรับปรุงในหลายด้านสำคัญ:
- ความเร็วและประสิทธิภาพ: SSDs ยุคแรกมีความเร็วในการอ่านและเขียนประมาณ 100 MB/s ในขณะที่ SSDs สมัยใหม่สามารถทำความเร็วได้ถึง 7000 MB/s. การเพิ่มขึ้นของความเร็วนี้เกิดจากความก้าวหน้าในเทคโนโลยีหน่วยความจำ NAND flash และการพัฒนาอินเทอร์เฟซที่เร็วขึ้น เช่น NVMe.
- ความจุ: SSDs ยุคแรกมีความจุเพียงไม่กี่กิกะไบต์ ในขณะที่ SSDs สมัยใหม่สามารถเก็บข้อมูลได้หลายเทระไบต์. การเพิ่มขึ้นของความจุนี้เป็นไปได้ด้วยความก้าวหน้าในเทคโนโลยีการผลิต ซึ่งช่วยให้สามารถจัดเก็บหน่วยความจำ NAND flash ได้หนาแน่นขึ้น.
- ฟอร์มแฟกเตอร์และอินเทอร์เฟซ: SSDs ได้ผ่านการเปลี่ยนแปลงในฟอร์มแฟกเตอร์และอินเทอร์เฟซเมื่อเวลาผ่านไป. เริ่มแรก SSDs ถูกออกแบบมาให้มีฟอร์มแฟกเตอร์เดียวกับฮาร์ดดิสก์ไดรฟ์แบบดั้งเดิม เช่น ขนาด 2.5 นิ้วและ 3.5 นิ้ว. อย่างไรก็ตาม เมื่อเทคโนโลยีก้าวหน้า ฟอร์มแฟกเตอร์ที่เล็กลงก็ถูกนำมาใช้ เช่น M.2 และ U.2 ซึ่งใช้ในแล็ปท็อปและอุปกรณ์อื่นๆ ที่มีพื้นที่จำกัด. นอกจากนี้ อินเทอร์เฟซใหม่ๆ เช่น PCIe ก็ได้รับการพัฒนาเพื่อให้สามารถถ่ายโอนข้อมูลได้เร็วยิ่งขึ้น.
SSDs มีบทบาทสำคัญในการประมวลผลสมัยใหม่ โดยเฉพาะอย่างยิ่งในแอปพลิเคชันที่ต้องการประสิทธิภาพสูง เช่น การฝึกอบรม AI และฐานข้อมูลขนาดใหญ่. การไม่มีชิ้นส่วนที่เคลื่อนไหวทำให้ SSDs ทนทานต่อแรงกระแทกและการสั่นสะเทือนได้ดีกว่า ทำให้เหมาะสำหรับอุปกรณ์พกพาและสภาพแวดล้อมที่สมบุกสมบัน. แม้ว่าโดยทั่วไปแล้ว SSDs จะมีราคาแพงกว่าต่อกิกะไบต์และมีจำนวนรอบการเขียนที่จำกัด แต่ข้อได้เปรียบด้านความเร็วและประสิทธิภาพทำให้เป็นตัวเลือกที่ต้องการสำหรับแอปพลิเคชันที่สำคัญ.
ข้อมูลขนาดใหญ่ (Big Data) และบทบาทต่อการพัฒนา LLM AI
ความต้องการข้อมูลปริมาณมหาศาลสำหรับการฝึก LLM
ถ้าไม่มี Big Data ก็คงไม่มี รากฐานสู่การวิวัฒน์ให้กับ LLM AI อย่างแท้จริง เพราะว่า … Large Language Models (LLMs) ต้องการชุดข้อมูลที่มีขนาดใหญ่ขึ้นเรื่อยๆ เพื่อประสิทธิภาพสูงสุด. ในทางปฏิบัติ ชุดข้อมูลเหล่านี้อาจรวมถึงข้อมูลหลายร้อยเทระไบต์ (TB) หรือแม้แต่เพตะไบต์ (PB). ตัวอย่างเช่น ชุดข้อมูล Common Crawl ต้องการข้อมูลประมาณ 7 เพตะไบต์ และขยายเพิ่มขึ้น 200TB ถึง 300TB ต่อเดือน. แม้แต่ชุดข้อมูลแบบเปิดที่ถูกลบซ้ำและทำความสะอาดแล้ว เช่น RedPajama-data-v2 ก็ยังต้องการพื้นที่จัดเก็บ 270TB.
ความต้องการข้อมูลมหาศาลนี้แตกต่างอย่างมากจากความสามารถในการจัดเก็บข้อมูลในอดีตอย่างสิ้นเชิง ในปี 1957 ฮาร์ดดิสก์ไดรฟ์ตัวแรก (IBM 350) มีความจุเพียง 3.75 เมกะไบต์. ในช่วงทศวรรษ 1970 ฟลอปปี้ดิสก์มีความจุเพียงไม่กี่ร้อยกิโลไบต์ถึง 1.2 เมกะไบต์. แม้กระทั่งแผ่น CD ที่เปิดตัวในปี 1982 ก็มีความจุเพียง 650 เมกะไบต์. การก้าวกระโดดจากเมกะไบต์และกิกะไบต์ในอดีตไปสู่เทระไบต์และเพตะไบต์ในปัจจุบัน แสดงให้เห็นถึงการเปลี่ยนแปลงครั้งใหญ่ในขีดความสามารถของการจัดเก็บข้อมูล ซึ่งเป็นสิ่งจำเป็นอย่างยิ่งสำหรับการฝึกอบรม LLM ที่มีพารามิเตอร์หลายพันล้านถึงหลายล้านล้านตัว.
LLMs เช่น Llama-2 7B ได้รับการฝึกอบรมล่วงหน้าด้วยโทเค็น 2 ล้านล้านโทเค็น. ในขณะที่ชุดข้อมูล BabyLM ที่มี 100 ล้านโทเค็นถูกเสนอว่าเป็นปริมาณ “ข้อมูลการฝึกอบรมล่วงหน้า” ที่สมเหตุสมผลสำหรับมนุษย์วัยรุ่น. การเปรียบเทียบนี้ชี้ให้เห็นว่า LLMs ต้องการข้อมูลจำนวนมากอย่างไม่น่าเชื่อเพื่อเรียนรู้ภาษาในระดับที่เทียบเท่าหรือเหนือกว่ามนุษย์ อย่างไรก็ตาม การวิจัยบางชิ้นชี้ให้เห็นว่าโมเดลขนาดใหญ่ต้องการข้อมูลน้อยลงอย่างมีนัยสำคัญเพื่อบรรลุระดับความคล่องแคล่วทางภาษาเดียวกัน. นอกจากนี้ ข้อมูลข้อความสามารถนำกลับมาใช้ใหม่ได้ถึงสี่ครั้งโดยไม่ทำให้ประสิทธิภาพของโมเดลลดลงอย่างเห็นได้ชัด และการเพิ่มงบประมาณการประมวลผลช่วยให้สามารถนำข้อมูลกลับมาใช้ใหม่ได้มากขึ้น. การปรับปรุงประสิทธิภาพข้อมูลนี้เป็นสิ่งสำคัญในการจัดการกับปริมาณข้อมูลที่เพิ่มขึ้นอย่างรวดเร็ว
ผลกระทบของความเร็วในการเข้าถึงข้อมูลต่อการประมวลผลและเรียนรู้ของ AI
ความเร็วในการเข้าถึงข้อมูลมีผลกระทบโดยตรงและสำคัญต่อประสิทธิภาพของการประมวลผลและการเรียนรู้ของ AI โดยเฉพาะอย่างยิ่งสำหรับ LLMs. โมเดล AI และ Machine Learning (ML) ต้องการข้อมูลปริมาณมหาศาลสำหรับการฝึกอบรมและการอนุมาน จึงจำเป็นต้องมีโซลูชันการจัดเก็บข้อมูลที่มีปริมาณงานสูง ความหน่วงต่ำ และคุ้มค่า.
ในกระบวนการฝึกอบรม LLM ข้อมูลที่ถูกแปลงเป็นโทเค็นจะถูกป้อนผ่านคลัสเตอร์ GPU ขนาดใหญ่เป็นชุดเล็กๆ. ในขณะที่ข้อมูลถูกประมวลผล น้ำหนักของโมเดลจะได้รับการอัปเดต และน้ำหนักเหล่านั้นจะถูกบันทึกเป็นจุดตรวจสอบไปยังที่จัดเก็บ. การเข้าถึงข้อมูลที่รวดเร็วเป็นสิ่งสำคัญอย่างยิ่งในขั้นตอนนี้ เนื่องจากความล่าช้าในการเข้าถึงข้อมูลสามารถสร้างคอขวดที่จำกัดประสิทธิภาพโดยรวมของการฝึกอบรมได้. ตัวอย่างเช่น การโหลดข้อมูลอินพุตและการบันทึกจุดตรวจสอบน้ำหนักของโมเดลจะอาศัย NVMe ในแต่ละโหนดเพื่อขจัดความล่าช้าที่เกิดจาก “เพื่อนบ้านที่มีเสียงดัง” (noisy neighbors). ข้อมูลอินพุตจะถูกจัดเก็บไปยังที่จัดเก็บในเครื่องเพียงครั้งเดียวเมื่อเริ่มต้นการฝึกอบรม และจุดตรวจสอบจะถูกส่งออกไปยังที่จัดเก็บที่ใช้ร่วมกันแบบอะซิงโครนัสโดยไม่ส่งผลกระทบต่อการใช้งาน GPU.
แม้ว่าในอดีตผู้จำหน่ายที่จัดเก็บข้อมูลจะยืนยันว่าการอ่านข้อมูลอินพุตซ้ำๆ แบบสุ่มในแต่ละขั้นตอนจำเป็นต้องมีระบบไฟล์แบบขนานที่เร็วสุดๆ เพื่อให้ทัน แต่ปัจจุบันสิ่งนี้ไม่เป็นความจริงเนื่องจากสองปัจจัยสำคัญ: ประการแรก ข้อมูลอินพุตไม่ได้เป็นไฟล์ข้อความหรือรูปภาพขนาดเล็กหลายล้านไฟล์ แต่ไฟล์ขนาดเล็กเหล่านี้จะถูกบรรจุลงในออบเจกต์ขนาดใหญ่ก่อนที่ GPU จะเห็น. ประการที่สอง ข้อมูลที่แปลงเป็นโทเค็นมีความหนาแน่นสูงมากเมื่อเทียบกับข้อมูลดิบ ดังนั้นปริมาณไบต์ที่อ่านตลอดหลายร้อยหรือหลายพันขั้นตอนจึงค่อนข้างน้อย. ตัวอย่างเช่น โมเดล Llama-3 405b ซึ่งฝึกอบรมด้วยโทเค็น 15.6 ล้านล้านโทเค็น ต้องการโหลดโทเค็นจากที่จัดเก็บเพียง 60 TB เท่านั้น ซึ่งแบ่งออกเป็น 3.75 GB ของโทเค็นที่ประมวลผลโดย GPU แต่ละตัวตลอดการทำงาน 54 วัน. สิ่งนี้แสดงให้เห็นว่าความท้าทาย I/O ที่ใหญ่ที่สุดในลูปการฝึกอบรมที่สำคัญต่อประสิทธิภาพไม่ใช่แบนด์วิดท์ดิบ แต่เป็นความแปรปรวนของประสิทธิภาพ.
โครงสร้างพื้นฐานการจัดเก็บข้อมูลแบบกระจายและคลาวด์สำหรับการพัฒนา LLM AI
การฝึกอบรมและการปรับใช้โมเดล AI ขนาดใหญ่ต้องการการถ่ายโอนข้อมูลจำนวนมหาศาลระหว่างโหนดการประมวลผลแบบกระจาย ระบบจัดเก็บข้อมูล และแพลตฟอร์มคลาวด์. โซลูชันเครือข่ายที่มีแบนด์วิดท์สูง เช่น InfiniBand และ Ethernet ความเร็วสูง ช่วยให้เวิร์กโหลด AI ทำงานได้อย่างราบรื่นโดยการลดคอขวดในการเคลื่อนย้ายข้อมูล.
แนวทางทั่วไปสำหรับการจัดการข้อมูลในโครงสร้างพื้นฐาน AI รวมถึง:
- Solid-state drives (SSDs): สำหรับการเข้าถึงข้อมูลความเร็วสูง.
- Object storage systems: สำหรับการจัดการข้อมูลที่ไม่มีโครงสร้างอย่างมีประสิทธิภาพ.
- Hybrid storage solutions: ที่รวมการจัดเก็บข้อมูลบนคลาวด์และในองค์กรเข้าด้วยกันเพื่อสร้างสมดุลระหว่างการเข้าถึงและความปลอดภัย.
Data Lakes และ Data Warehouses มีบทบาทสำคัญในโซลูชันโครงสร้างพื้นฐาน AI โดยให้การจัดเก็บข้อมูลที่มีโครงสร้างและการเรียกใช้ข้อมูลการฝึกอบรมที่ง่ายดาย. Data lakes จัดเก็บข้อมูลดิบที่ไม่มีโครงสร้างในรูปแบบดั้งเดิม ทำให้เหมาะสำหรับแอปพลิเคชันการเรียนรู้เชิงลึกที่ต้องการแหล่งข้อมูลที่หลากหลาย. Data warehouses จัดโครงสร้างข้อมูลสำหรับการสืบค้นและการวิเคราะห์ที่รวดเร็ว ทำให้มั่นใจได้ถึงการประมวลผลที่มีประสิทธิภาพสำหรับข้อมูลเชิงลึกที่ขับเคลื่อนด้วย AI.
วิศวกรโครงสร้างพื้นฐาน AI ใช้กลยุทธ์ต่างๆ เช่น การทำดัชนีและการแคชเพื่อเร่งความเร็วในการเรียกใช้ข้อมูล. นอกจากนี้ ยังมีการใช้ไปป์ไลน์ข้อมูลอัตโนมัติเพื่อปรับปรุงกระบวนการเตรียมข้อมูลและการนำเข้าข้อมูล. การเรียนรู้แบบรวมศูนย์ (Federated learning) ช่วยให้การฝึกอบรม AI แบบกระจายอำนาจเป็นไปได้โดยไม่กระทบต่อความเป็นส่วนตัวของข้อมูล.
การประมวลผลแบบกระจาย (Distributed computing) โดยใช้โซลูชันบนคลาวด์และคลัสเตอร์แบบหลายโหนด ช่วยกระจายเวิร์กโหลด AI ได้อย่างมีประสิทธิภาพ. การจัดสรรทรัพยากรแบบไดนามิกช่วยให้โซลูชันโครงสร้างพื้นฐาน AI มีความยืดหยุ่นในการปรับขนาดพลังการประมวลผลตามความต้องการแบบเรียลไทม์. การนำ AI ไปใช้ในรูปแบบคลาวด์แบบกระจายช่วยลดความหน่วงและเพิ่มการตอบสนองโดยการนำ AI เข้าใกล้ผู้ใช้มากขึ้น ซึ่งลดความจำเป็นในการถ่ายโอนข้อมูลไปมาระหว่างศูนย์ข้อมูลคลาวด์แบบรวมศูนย์. สิ่งนี้ไม่เพียงช่วยลดความแออัดของเครือข่าย แต่ยังนำไปสู่การประหยัดต้นทุนอย่างมากในการถ่ายโอนและจัดเก็บข้อมูล.
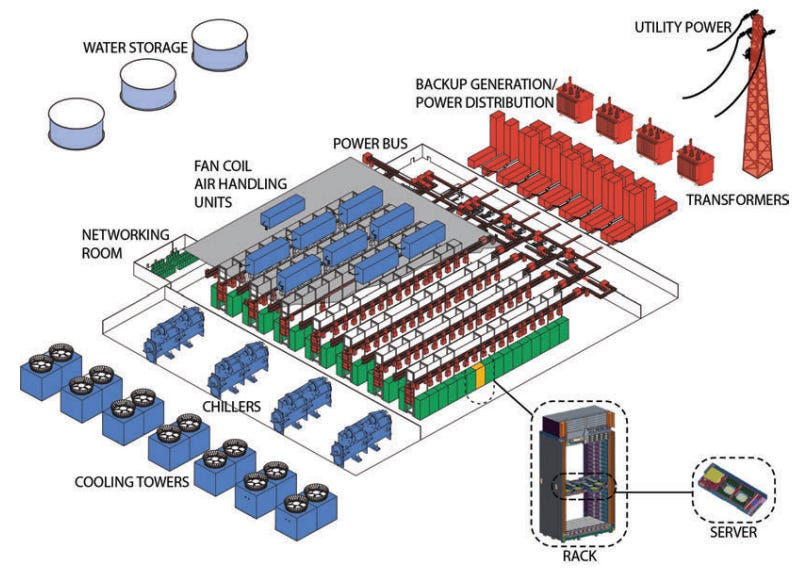
Typical layout of a large data center, via “The Datacenter as a Computer.”
แนวโน้มและอนาคตของการจัดเก็บข้อมูลสำหรับ AI
เทคโนโลยีการจัดเก็บข้อมูลที่เกิดขึ้นใหม่ รากฐานสู่การวิวัฒน์ให้กับ LLM AI
ภูมิทัศน์ของการจัดเก็บข้อมูลมีการพัฒนาอย่างรวดเร็ว โดยมีนวัตกรรมทางเทคโนโลยีอย่างต่อเนื่องและความต้องการแอปพลิเคชันที่เปลี่ยนแปลงไปอย่างรวดเร็ว. ความต้องการความจุในการจัดเก็บข้อมูลที่เพิ่มขึ้นอย่างต่อเนื่องได้รับผลกระทบจากการใช้งานอุปกรณ์ IoT การประมวลผลข้อมูลแบบเรียลไทม์ และการจัดเก็บข้อมูลบนคลาวด์ที่เพิ่มขึ้น. ภายในสิ้นปี 2025 ปริมาณข้อมูลทั่วโลกคาดว่าจะเพิ่มขึ้นเป็น 181 ซิกะไบต์ (Zettabytes).
เทคโนโลยีการจัดเก็บข้อมูลที่เกิดขึ้นใหม่กำลังสำรวจวิธีการใหม่ๆ ในการจัดเก็บข้อมูลเพื่อตอบสนองความต้องการที่เพิ่มขึ้นของ AI:
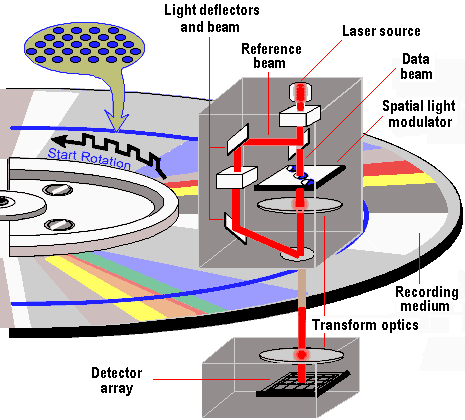
Holographic Data Storage
- Holographic Data Storage: เทคนิคนี้บันทึกข้อมูลเป็นโฮโลแกรม ซึ่งเป็นการแสดงแสงสามมิติ. โฮโลแกรมถูกสร้างขึ้นโดยการตัดกันของลำแสงเลเซอร์สองลำภายในสื่อบันทึก. เทคโนโลยีนี้มีศักยภาพในการจัดเก็บข้อมูลที่มีความหนาแน่นสูง (สูงสุด 1 Tbit/cm³) อัตราการถ่ายโอนข้อมูลที่รวดเร็ว (สูงสุด 1 Gbps) และการใช้พลังงานต่ำ. นอกจากนี้ยังมีความทนทานของข้อมูลสูงและสามารถเก็บข้อมูลได้ในระยะยาว. Holographic data storage มีศักยภาพในการปฏิวัติการจัดเก็บข้อมูลบนคลาวด์และศูนย์ข้อมูล โดยให้โซลูชันการจัดเก็บข้อมูลที่มีขนาดกะทัดรัดและมีประสิทธิภาพสูง. การวิจัยของ IBM ได้แสดงให้เห็นถึงศักยภาพในการจัดเก็บข้อมูลได้ถึง 1 TB ภายในคริสตัลขนาดเท่าก้อนน้ำตาล โดยมีอัตราการถ่ายโอนข้อมูลสูงถึงหนึ่งล้านล้านบิตต่อวินาที. คาดว่าจะมีคุณค่าในการใช้งานการจัดเก็บข้อมูลถาวรหรือห้องสมุดที่ต้องการเก็บข้อมูลปริมาณมากด้วยต้นทุนที่ต่ำที่สุดเท่าที่จะเป็นไปได้.
- DNA Data Storage: เทคโนโลยีที่เกิดขึ้นใหม่นี้ใช้ประโยชน์จากโมเลกุล DNA ในการจัดเก็บข้อมูลดิจิทัล ซึ่งให้ความหนาแน่นในการจัดเก็บข้อมูลที่น่าทึ่ง ความทนทานที่ไม่มีใครเทียบได้ และต้นทุนด้านสิ่งแวดล้อมที่ต่ำกว่าอย่างมาก. DNA สามารถคงอยู่ได้หลายชั่วอายุคน ต่างจาก NAND flash และ HDDs ที่เสื่อมสภาพในไม่กี่ปีหรือหลายสิบปี. นอกจากนี้ยังมีความจุข้อมูลสูงกว่าระบบจัดเก็บข้อมูลทั่วไปประมาณ 100 ล้านเท่า. การจัดเก็บข้อมูลด้วย DNA สามารถบีบอัดความหนาแน่นของข้อมูลได้ถึงจุดที่คอนเทนเนอร์ขนาดเมกะไบต์เดียวสามารถจัดเก็บข้อมูลได้ถึง 100 เทระไบต์ในทางทฤษฎี. แม้ว่าการเรียกใช้ข้อมูลจากที่จัดเก็บ DNA จะเป็นกระบวนการที่ซับซ้อนและค่อนข้างช้า แต่ความก้าวหน้าล่าสุดได้นำเสนอเครื่องมือ AI ที่ชื่อว่า DNAformer ซึ่งช่วยเร่งกิจกรรมนี้ได้ถึง 3,200 เท่า และเพิ่มความแม่นยำได้ถึง 40%. DNAformer ใช้ประโยชน์จากโครงข่ายประสาทเทียมแบบ transformer ซึ่งเป็นสถาปัตยกรรม AI ที่เชี่ยวชาญในการจดจำรูปแบบในข้อมูลจำนวนมาก เพื่อสร้างลำดับ DNA ที่ถูกต้องจากการคัดลอกที่ผิดพลาด. การปรับปรุงความเร็วและความแม่นยำนี้อาจทำให้การจัดเก็บข้อมูลด้วย DNA เป็นตัวเลือกที่ใช้งานได้จริงสำหรับการใช้งานขนาดใหญ่ในอนาคต.
ความท้าทายและโอกาสในอนาคต
การเติบโตอย่างไม่หยุดยั้งของข้อมูลที่ขับเคลื่อนโดย AI กำลังสร้างแรงกดดันอย่างไม่เคยมีมาก่อนต่อระบบจัดเก็บข้อมูลเพื่อให้สามารถรองรับทั้งความจุและประสิทธิภาพ. โมเดล Machine Learning, Generative AI และการวิเคราะห์แบบเรียลไทม์ ล้วนขึ้นอยู่กับชุดข้อมูลขนาดใหญ่สำหรับการฝึกอบรมและการดำเนินงานอย่างต่อเนื่อง. ขนาดของชุดข้อมูลการฝึกอบรม AI ได้เติบโตแบบทวีคูณ โดยขนาดชุดข้อมูลเฉลี่ยเพิ่มขึ้นจาก 42 พันล้านจุดข้อมูลในปี 2021 เป็นมากกว่า 750 พันล้านจุดในปี 2023 และมีแนวโน้มที่จะเพิ่มขึ้นอีก.
เพื่อรับมือกับความท้าทายนี้ องค์กรต่างๆ กำลังหันไปใช้สถาปัตยกรรมการจัดเก็บข้อมูลที่สร้างขึ้นเพื่อ AI โดยเฉพาะ เทคโนโลยีเช่น NVMe over Fabrics (NVMe-oF) ช่วยให้สามารถถ่ายโอนข้อมูลได้รวดเร็วเป็นพิเศษและมีความหน่วงต่ำ ซึ่งเป็นสิ่งสำคัญสำหรับเวิร์กโหลด AI ที่ต้องการการเข้าถึงชุดข้อมูลขนาดใหญ่ได้อย่างรวดเร็ว. SSDs เฉพาะทางกำลังเกิดขึ้น โดยนำเสนอ Input/Output Operations Per Second (IOPS) ที่สูงขึ้นและเส้นทางข้อมูลที่ปรับให้เหมาะสมสำหรับแอปพลิเคชัน AI. ในขณะเดียวกัน HDDs ที่มีความจุสูงยังคงมีบทบาทสำคัญในการรองรับความต้องการจัดเก็บข้อมูลจำนวนมากของเวิร์กโหลด AI โดยให้โซลูชันที่เชื่อถือได้ ปรับขนาดได้ และคุ้มค่าสำหรับการจัดเก็บข้อมูลระยะยาวและการเก็บถาวร.
นอกจากนี้ ความยั่งยืนยังเป็นข้อพิจารณาที่สำคัญในอนาคตของการจัดเก็บข้อมูลสำหรับ AI. AI, ML และ IoT ใช้พลังงานจำนวนมหาศาลทั้งในการประมวลผลและจัดเก็บข้อมูลที่เพิ่มขึ้นอย่างต่อเนื่อง. ศูนย์ข้อมูลคิดเป็นประมาณสามเปอร์เซ็นต์ของการใช้ไฟฟ้าทั่วโลก. การอัปเกรดเป็นไดรฟ์จัดเก็บข้อมูลที่มีความจุสูงขึ้น เช่น การเปลี่ยนจาก 26TB ePMR HDDs เป็น 32TB UltraSMR HDDs สามารถประหยัดพลังงานได้อย่างมาก. SSDs แม้จะมีราคาเริ่มต้นที่สูงกว่า แต่ก็สามารถประหยัดพลังงานได้มากตลอดอายุการใช้งาน โดยเฉพาะอย่างยิ่งสำหรับเวิร์กโหลดที่มีประสิทธิภาพสูง. แนวปฏิบัติในการจัดการข้อมูล เช่น การลดข้อมูลซ้ำซ้อนและการบีบอัด ยังช่วยลดความต้องการจัดเก็บข้อมูล ซึ่งช่วยลดทั้งพลังงานและค่าใช้จ่ายในการระบายความร้อน.
อนาคตของการจัดเก็บข้อมูลสำหรับ AI มุ่งเน้นไปที่การสร้างสมดุลระหว่างความต้องการความจุที่เพิ่มขึ้น ความเร็วที่รวดเร็ว และความยั่งยืนด้านสิ่งแวดล้อม การพัฒนาอย่างต่อเนื่องในเทคโนโลยีที่มีอยู่และเทคโนโลยีที่เกิดขึ้นใหม่ เช่น Holographic และ DNA storage จะกำหนดว่า LLMs และ AI โดยรวมจะสามารถพัฒนาไปได้ไกลแค่ไหนในอีกหลายทศวรรษข้างหน้า
บทสรุป
การเดินทางของเทคโนโลยี รากฐานสู่การวิวัฒน์ให้กับ LLM AI การบันทึกข้อมูลของระบบคอมพิวเตอร์เป็นเรื่องราวของการเอาชนะข้อจำกัดอย่างต่อเนื่องเพื่อปลดล็อกศักยภาพการประมวลผลที่เพิ่มขึ้น ตั้งแต่บัตรเจาะรูที่เรียบง่ายซึ่งเป็นตัวแทนของข้อมูลไบนารีในยุคแรกเริ่ม ไปจนถึงเทปแม่เหล็กที่นำมาซึ่งการจัดการข้อมูลอัตโนมัติ และหน่วยความจำคอร์ที่ปฏิวัติการเข้าถึงแบบสุ่ม แต่ละยุคสมัยได้สร้างรากฐานที่สำคัญสำหรับการก้าวหน้าครั้งต่อไป
การถือกำเนิดของฮาร์ดดิสก์ไดรฟ์ได้สร้างมาตรฐานสำหรับการจัดเก็บข้อมูลทุติยภูมิ โดยนำเสนอความจุและความเร็วที่เพิ่มขึ้นอย่างทวีคูณ ในขณะที่ฟลอปปี้ดิสก์และแผ่นดิสก์ออปติคัลได้ทำให้การจัดเก็บข้อมูลเข้าถึงได้ง่ายขึ้นและพกพาได้มากขึ้นสำหรับผู้ใช้ทั่วไป อย่างไรก็ตาม การเปลี่ยนแปลงที่สำคัญที่สุดเกิดขึ้นด้วยหน่วยความจำแฟลชและโซลิดสเตตไดรฟ์ (SSDs) ซึ่งนำเสนอความเร็วและความทนทานที่ไม่มีใครเทียบได้ โดยขจัดข้อจำกัดด้านกลไกของเทคโนโลยีรุ่นก่อนๆ
ความก้าวหน้าเหล่านี้มีความสำคัญอย่างยิ่งต่อการวิวัฒนาการของ Large Language Models (LLMs) และ AI โดยรวม LLMs ต้องการข้อมูลปริมาณมหาศาลในระดับเทระไบต์และเพตะไบต์สำหรับการฝึกอบรม ซึ่งเป็นปริมาณที่ไม่อาจจินตนาการได้ด้วยเทคโนโลยีการจัดเก็บข้อมูลในอดีต ความเร็วในการเข้าถึงข้อมูลที่รวดเร็วเป็นสิ่งจำเป็นสำหรับการประมวลผลและเรียนรู้ของ AI อย่างมีประสิทธิภาพ และโครงสร้างพื้นฐานการจัดเก็บข้อมูลแบบกระจายและคลาวด์ได้กลายเป็นสิ่งจำเป็นสำหรับการจัดการชุดข้อมูลขนาดใหญ่เหล่านี้
มองไปข้างหน้า เทคโนโลยีการจัดเก็บข้อมูลยังคงพัฒนาอย่างต่อเนื่องเพื่อตอบสนองความต้องการที่เพิ่มขึ้นของ AI เทคโนโลยีที่เกิดขึ้นใหม่ เช่น Holographic data storage และ DNA data storage สัญญาว่าจะนำเสนอความหนาแน่นและความทนทานที่เหนือกว่า ซึ่งอาจปฏิวัติการจัดเก็บข้อมูลอีกครั้งในอนาคต อย่างไรก็ตาม ความท้าทายยังคงมีอยู่ในการสร้างสมดุลระหว่างความจุ ประสิทธิภาพ และความยั่งยืนด้านสิ่งแวดล้อมของระบบจัดเก็บข้อมูล การเดินทางของนวัตกรรมการจัดเก็บข้อมูลยังคงเป็นแรงขับเคลื่อนที่สำคัญในการกำหนดขีดจำกัดของสิ่งที่ AI สามารถทำได้ในอนาคต